The decision crystallized over a single weekend in 2019. I was sitting in a cafe in Kuala Lumpur, staring at two browser tabs. The left tab had the Society of Actuaries exam schedule for the next three years -- a clear, well-trodden path toward a comfortable career in insurance pricing. The right tab had a Jupyter notebook where I had just trained a gradient boosting model to predict credit defaults with an AUC of 0.89 on a Kaggle dataset.
The actuarial path promised stability. The machine learning path promised I would never be bored.
I closed the left tab.
The Pivot Point
That decision has shaped every part of my career since then, from building ML models at Credit Bureau Malaysia to architecting agentic AI systems at Infomina. And the counterintuitive truth is that the actuarial and statistical training I "left behind" has become the most valuable part of my toolkit.
The Path That Was Not a Straight Line
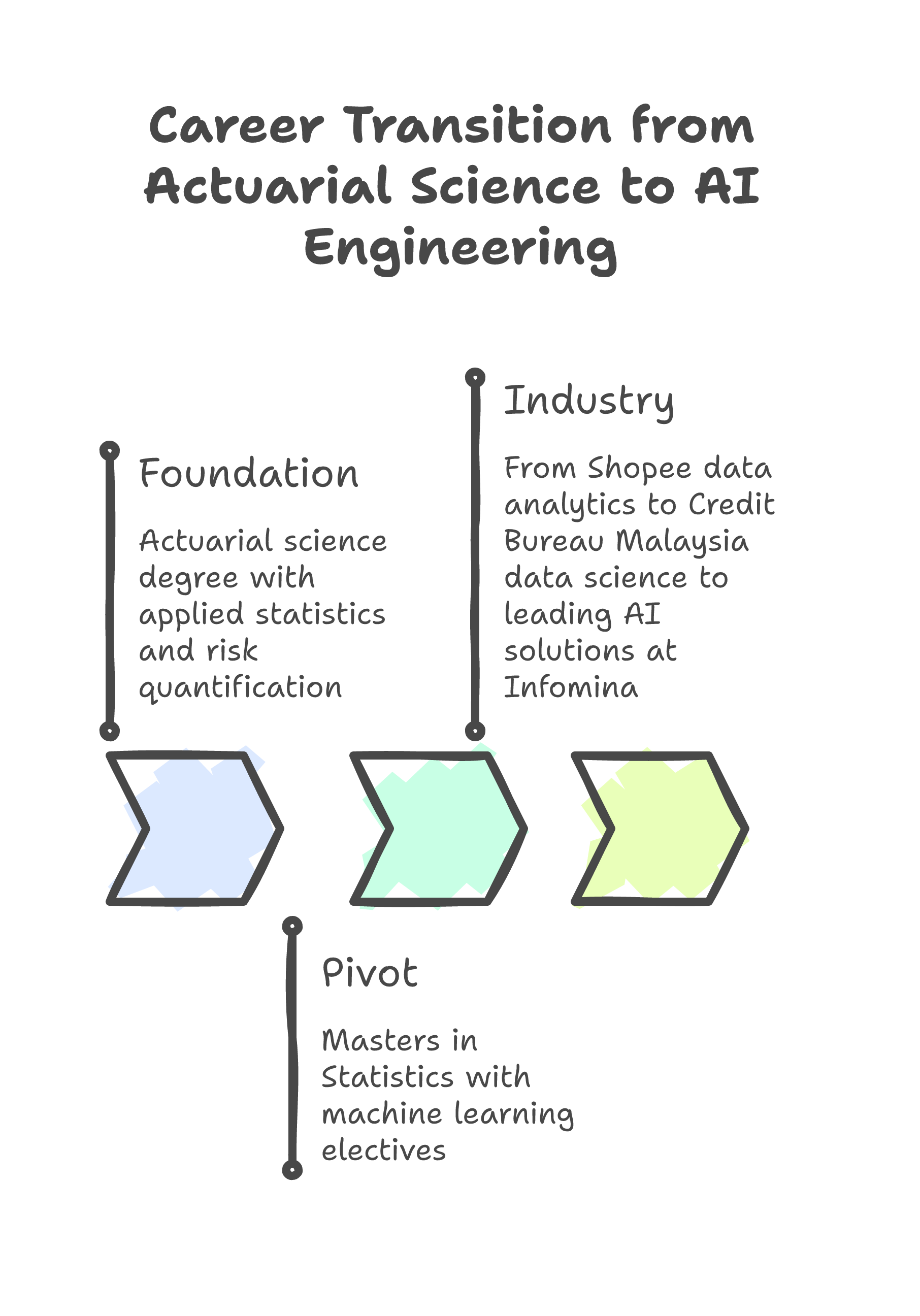
Let me be clear: I did not wake up one morning and decide to become an AI engineer. The transition happened in stages, each one building on the last.
Stage 1: The Foundation. I studied actuarial science at UTAR, graduating first in class. Actuarial science is, at its core, applied statistics with financial consequences. You learn probability theory, stochastic modeling, survival analysis, and risk quantification. You also learn that when your model is wrong, real money is lost.
Stage 2: The Pivot. During my MSc in Statistics at Universiti Malaya (again, First Class, because the statistical foundations demanded nothing less), I took every machine learning elective available. The overlap between classical statistics and ML was larger than either community likes to admit. Logistic regression is still logistic regression whether you call it a "statistical model" or a "classifier."
Stage 3: The Industry. My first industry role was at Shopee Malaysia in data analytics. Then I moved to Credit Bureau Malaysia as a data scientist, where I built production ML models on financial data at scale. Now I lead AI solutions at Infomina, building the agentic AI systems I write about in this blog.
The path from actuarial science to AI looks like a pivot from the outside. From the inside, it felt like a continuous deepening of the same core question: how do you make good decisions under uncertainty?
The Core Question
How Statistical Rigor Becomes a Superpower in AI
Here is what I have noticed working alongside engineers who came to AI from pure software backgrounds: they are often excellent at building systems but less rigorous about validating whether those systems work correctly.
Statistical training gives you a set of reflexes that are extraordinarily useful in AI:
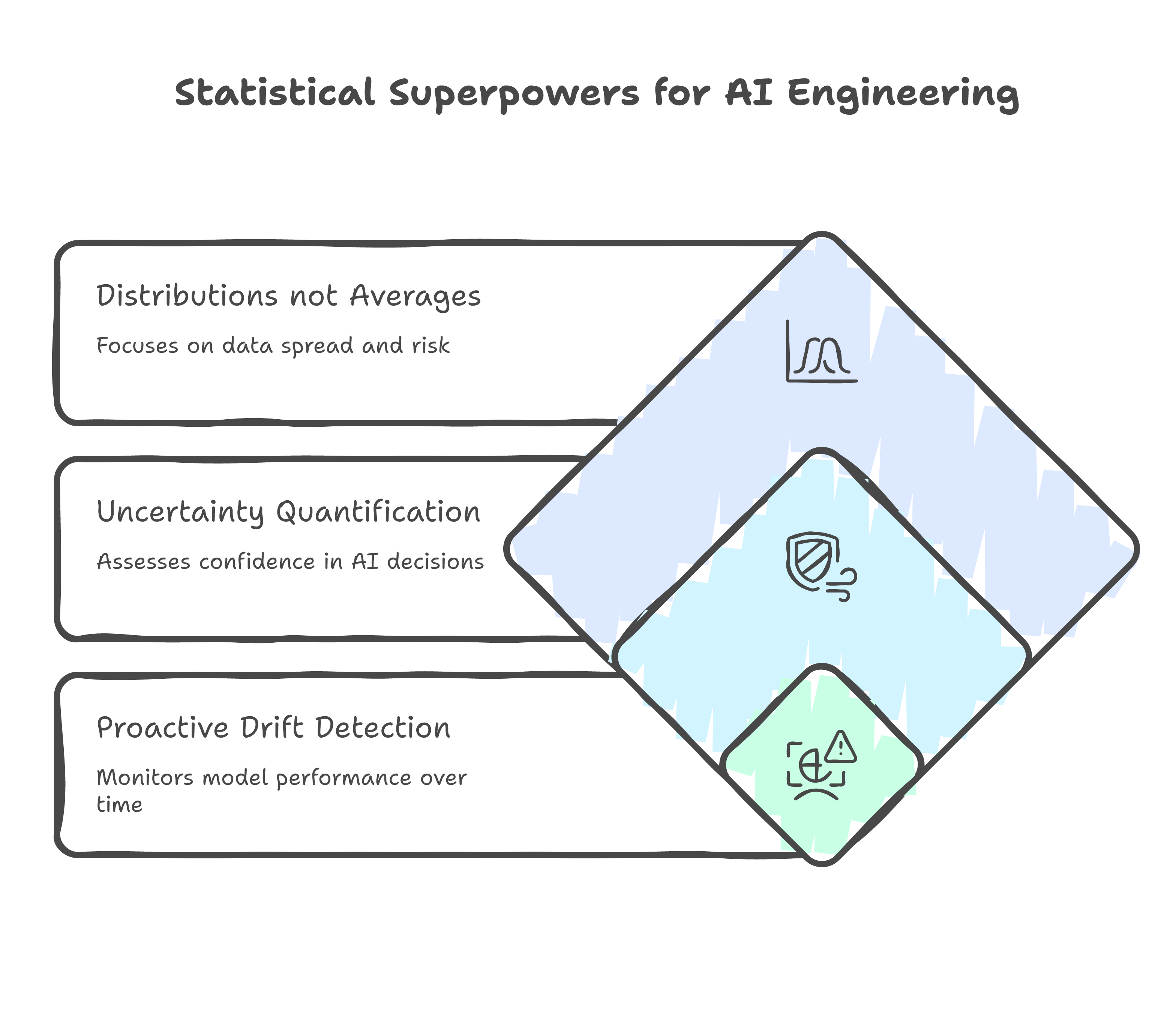
1. You Obsess Over Distributions, Not Just Averages
When someone tells me their model achieves "92% accuracy," my first question is: what is the class distribution? A model that predicts "no fraud" for every transaction achieves 99.5% accuracy on a dataset where 0.5% of transactions are fraudulent. Actuarial training beats this into you -- you learn to think about tail risks, not central tendencies.
In practice, this means I spend more time on precision-recall curves, calibration plots, and confusion matrices than most engineers consider necessary. It also means our models perform better in production, where the edge cases are what matter.
2. You Understand Uncertainty Quantification
Most ML models output a point prediction. Actuarial models output a distribution. When I build AI systems, I always push for confidence intervals, prediction intervals, or at minimum, calibrated probability scores.
This matters enormously for agentic AI. When our routing agent at AiMod says "I am 85% confident this is a data profiling task," that number needs to mean something. If the model says 85% and it is right 60% of the time, your confidence scores are miscalibrated and your escalation logic is broken.
# Calibration matters: Expected vs. observed accuracy at each confidence bin
def calibration_report(predictions, actuals, n_bins=10):
bins = np.linspace(0, 1, n_bins + 1)
for i in range(n_bins):
mask = (predictions >= bins[i]) & (predictions < bins[i + 1])
if mask.sum() > 0:
expected = predictions[mask].mean()
observed = actuals[mask].mean()
print(f"Bin [{bins[i]:.1f}, {bins[i+1]:.1f}): "
f"Expected={expected:.3f}, Observed={observed:.3f}, "
f"Gap={abs(expected - observed):.3f}, n={mask.sum()}")
3. You Think About Drift Before It Happens
Actuaries build models that need to work for 20+ years (life insurance pricing). You learn to think about regime changes, distributional drift, and the difference between interpolation and extrapolation.
In AI, model drift is a known problem that most teams only address reactively -- they wait until performance degrades and then investigate. My instinct is to monitor for drift proactively: track feature distributions over time, run statistical tests (PSI, KL divergence, KS tests) on incoming data, and alert before the model output degrades.
At Credit Bureau Malaysia, we caught a significant drift in our credit scoring model three weeks before it would have affected regulatory reports. The source? A banking partner changed their internal risk grading scale without notifying us. Our distribution monitoring flagged the shift in the risk_grade feature distribution before it propagated to the model output.
Early Drift Detection in Practice
The FRM and CFA Perspective on Risk in AI
I hold the Financial Risk Manager (FRM) certification and I am currently a CFA Level 3 candidate. These are not typical credentials for someone building AI systems, but they give me a perspective that I think is increasingly important as AI moves into regulated industries.
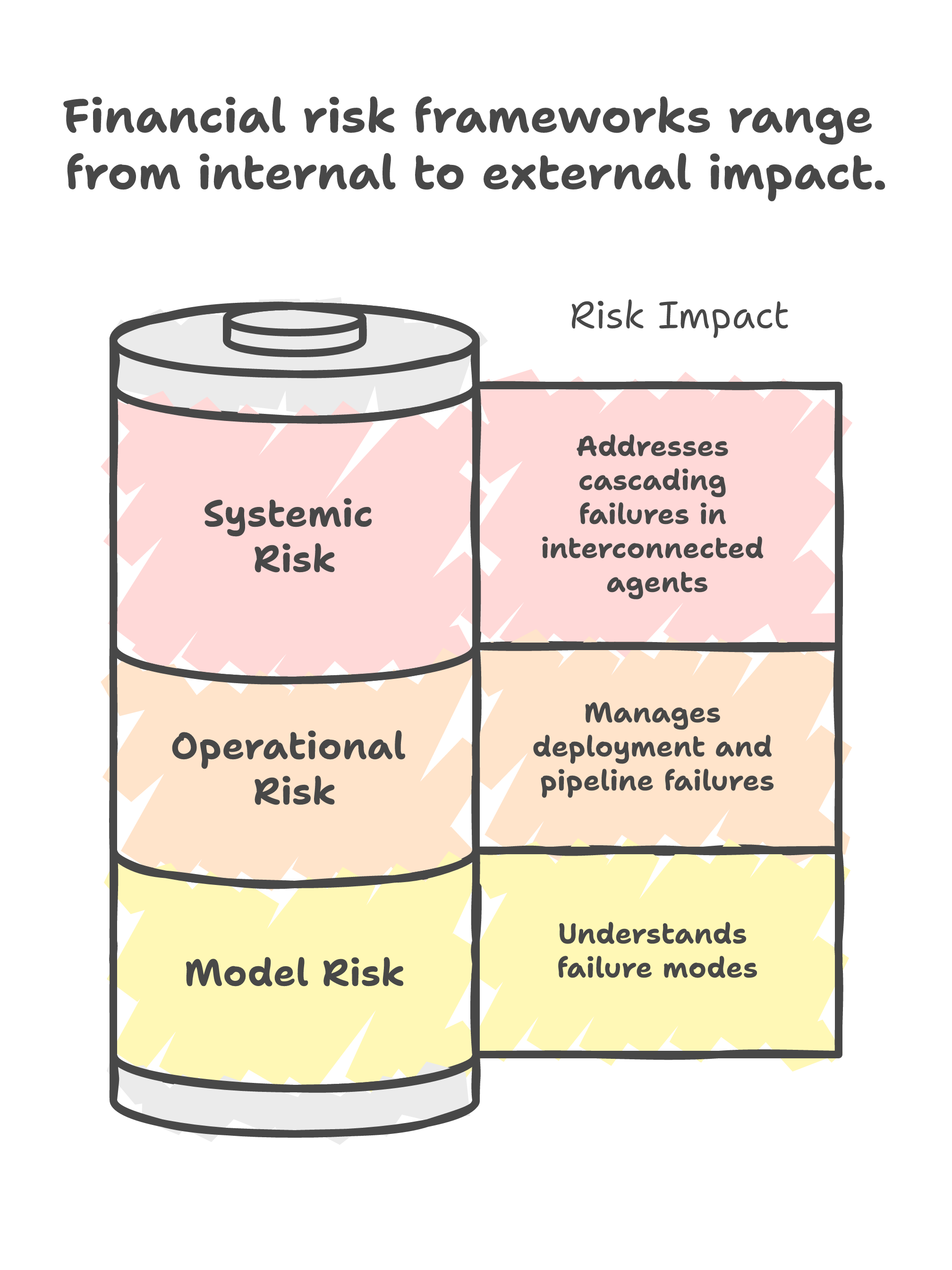
The FRM curriculum covers operational risk, model risk, and systemic risk -- concepts that translate directly to AI system design:
Model risk in AI is about more than accuracy. It is about understanding the conditions under which your model fails, quantifying the business impact of those failures, and having fallback mechanisms in place. Every AI system I build has a documented model risk assessment: what are the failure modes, what is the severity of each, and what mitigations are in place?
Operational risk maps directly to MLOps. How do you ensure your model is deployed correctly? What happens when the data pipeline breaks? How do you roll back a model that is misbehaving in production? These are standard questions in financial risk management, and they should be standard questions in AI engineering.
Systemic risk is the one that keeps me up at night. As AI agents become more interconnected (calling other APIs, triggering other agents, making autonomous decisions), the potential for cascading failures increases. The same dynamics that caused the 2008 financial crisis -- tight coupling, hidden dependencies, insufficient circuit breakers -- can appear in complex AI systems.
Advice for Career Changers
If you are considering a similar pivot, here is what I have learned:
Your Background Is Your Edge
Your existing expertise is not a detour -- it is a differentiator. The market is flooded with people who can train a model. There are far fewer people who can train a model and think rigorously about risk, uncertainty, and long-term reliability. Whatever your background -- finance, physics, biology, engineering -- bring it with you.
Learn the engineering, not just the algorithms. The gap between a Jupyter notebook and a production system is vast. Docker, Kubernetes, CI/CD pipelines, database optimization, API design -- these are the skills that separate someone who can prototype from someone who can ship. I spent deliberate time learning FastAPI, Docker, and infrastructure orchestration, and it has been at least as valuable as any ML algorithm I studied.
Build things that work, not things that impress. Kaggle competitions and toy projects are fine for learning, but what actually advances your career is building something that solves a real problem for a real user. My first production model at Credit Bureau Malaysia was a relatively simple logistic regression. It was not impressive. But it ran reliably every day, produced calibrated probabilities, and informed real lending decisions. That matters more than a state-of-the-art architecture that crashes in production.
The transition is a marathon, not a sprint. It took me roughly three years to go from "data analyst with some ML skills" to "AI solutions lead building production systems." There were periods of impostor syndrome, late nights learning new tools, and moments where the actuarial path looked a lot more comfortable. Every career change has these. They pass.
Where Statistics Meets the Future
The irony is that as AI gets more sophisticated, the need for statistical rigor increases, not decreases. Large language models hallucinate. Agentic systems make autonomous decisions with real consequences. The questions become: How do you validate an agent's decisions? How do you quantify the uncertainty in a RAG system's output? How do you detect when a model has drifted from its intended behavior?
These are fundamentally statistical questions. And they are the questions I find most interesting in my work today.
If you are considering a similar career transition, or if you are already in AI and want to strengthen your statistical foundations, I would love to hear from you. The best conversations happen at the intersection of disciplines.