I made an error in a published article. A reader said that proved a machine wrote it.
I published an article about AI coding tool adoption last month. A few thousand reads. A few dozen comments. One I am still thinking about.
A commenter spotted an error in my piece and wrote: "The fact that the author also can't count means that it's likely an ai written article."
The error was real. But the leap caught me off guard. A mistake in a published article is no longer evidence of a tired author or a missed edit. It is evidence of a machine. Human fallibility is no longer accepted as human. It requires an explanation now. And the default explanation is: a machine did it.
If you have ever second-guessed your own writing because you worried someone might call it AI, you know this feeling. The scrutiny is not just pointed at machines. It is pointed at anyone who might be using one.
We do not treat these errors the same
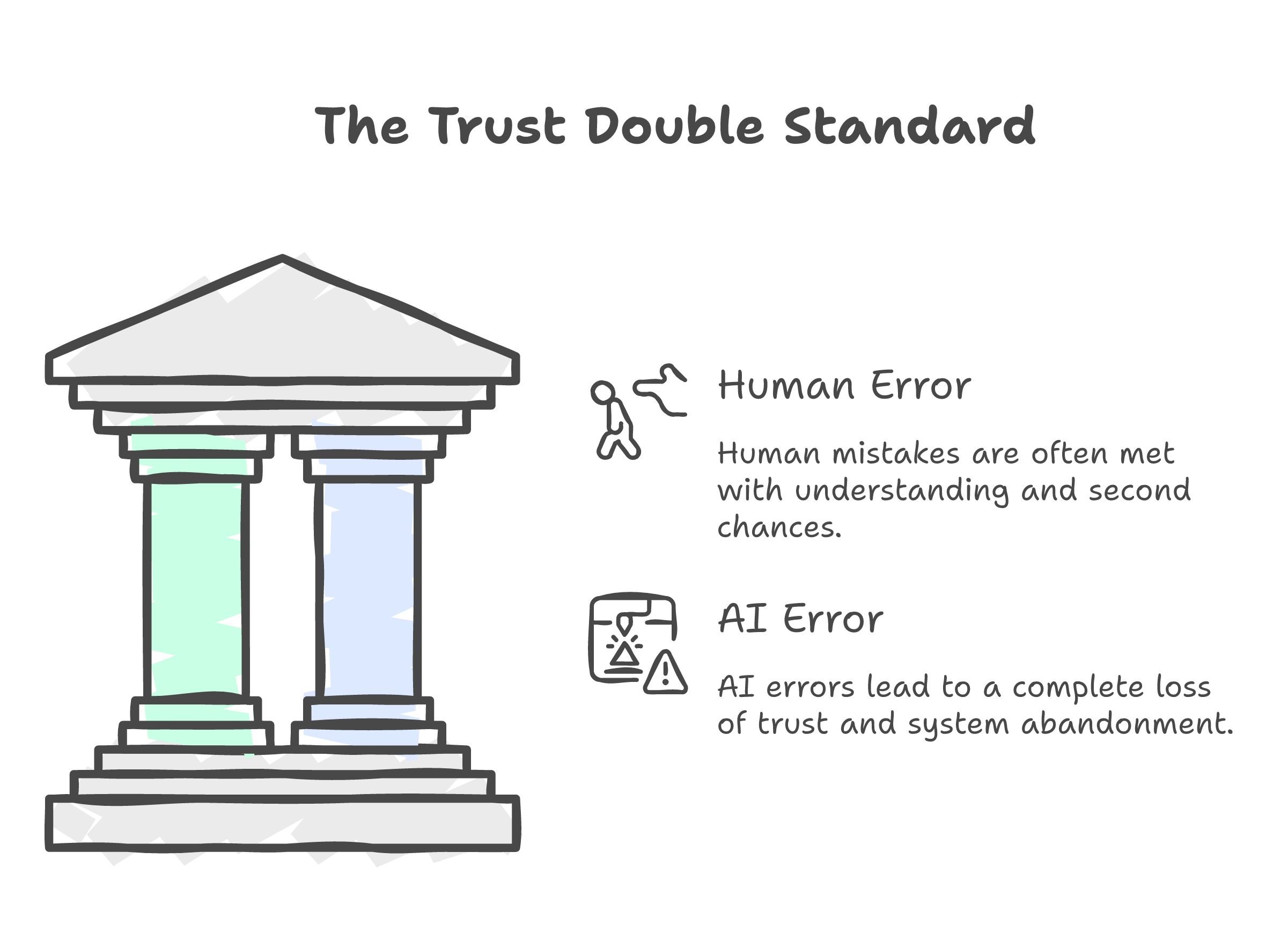
There is a fair counterpoint here. Context matters. A medical error carries more weight than a typo. Scrutiny should scale with consequence. I agree.
But we do not actually scale it that way.
A 2026 PMC study on human-AI financial advisory tested this directly. Researchers gave AI and human advisors the same task. When they made identical errors, the AI lost trust faster and more permanently. Same mistake. Same outcome. Different verdict.
That is not rational risk assessment. It is pattern recognition misfiring. We see an error and reach for the most available explanation. Right now, "AI did it" is the most available explanation for almost anything that feels off.
McKinsey's 2026 State of AI Trust report has a name for this: "the agentic trust gap." AI systems get more capable, but trust does not follow. Not because they fail more often. Because we watch them more closely.
The standard is not higher because AI is worse. It is higher because we have not learned how to trust something that does not have a pulse.
The investment tells the real story
One number explains more than any trust survey.
Companies allocate 93% of their AI adoption budgets to technology. Seven percent goes to helping humans actually work with it.
93 to 7. You cannot build trust in a system you never taught people to use. That is not a trust problem. That is an investment problem wearing a trust costume.
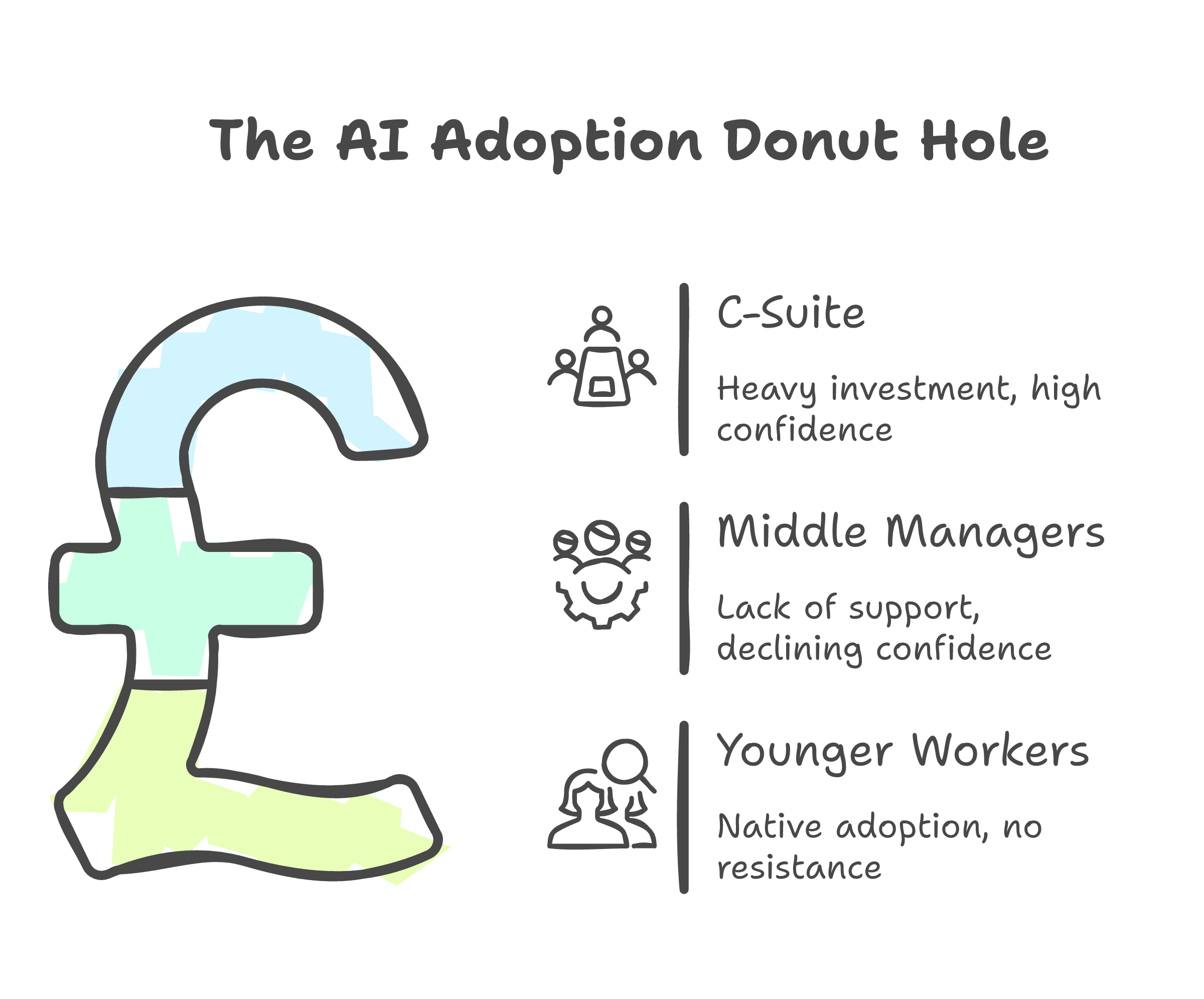
Wharton research found what they call the "donut hole." Executives invest in AI. Younger workers adopt it natively. Middle managers, the ones who actually have to change how work gets done, get left behind. Baby boomers saw a 35% drop in AI confidence last year. Gen X dropped 25%.
These are not Luddites. These are people who built expertise over decades watching it become potentially irrelevant overnight. With no clear path to rebuild. The distrust is not irrational from where they sit. But I do not think it is really about error rates. I think it is about displacement. The quality concern is real, but it is not the whole story.
I have seen this pattern up close. The pushback is never "I tried it and it failed." It is "it is not perfect." The tool does not need to be perfect. It needs to be better than not using it. But that comparison rarely happens.
The part the skeptics get right
The discomfort is not irrational.
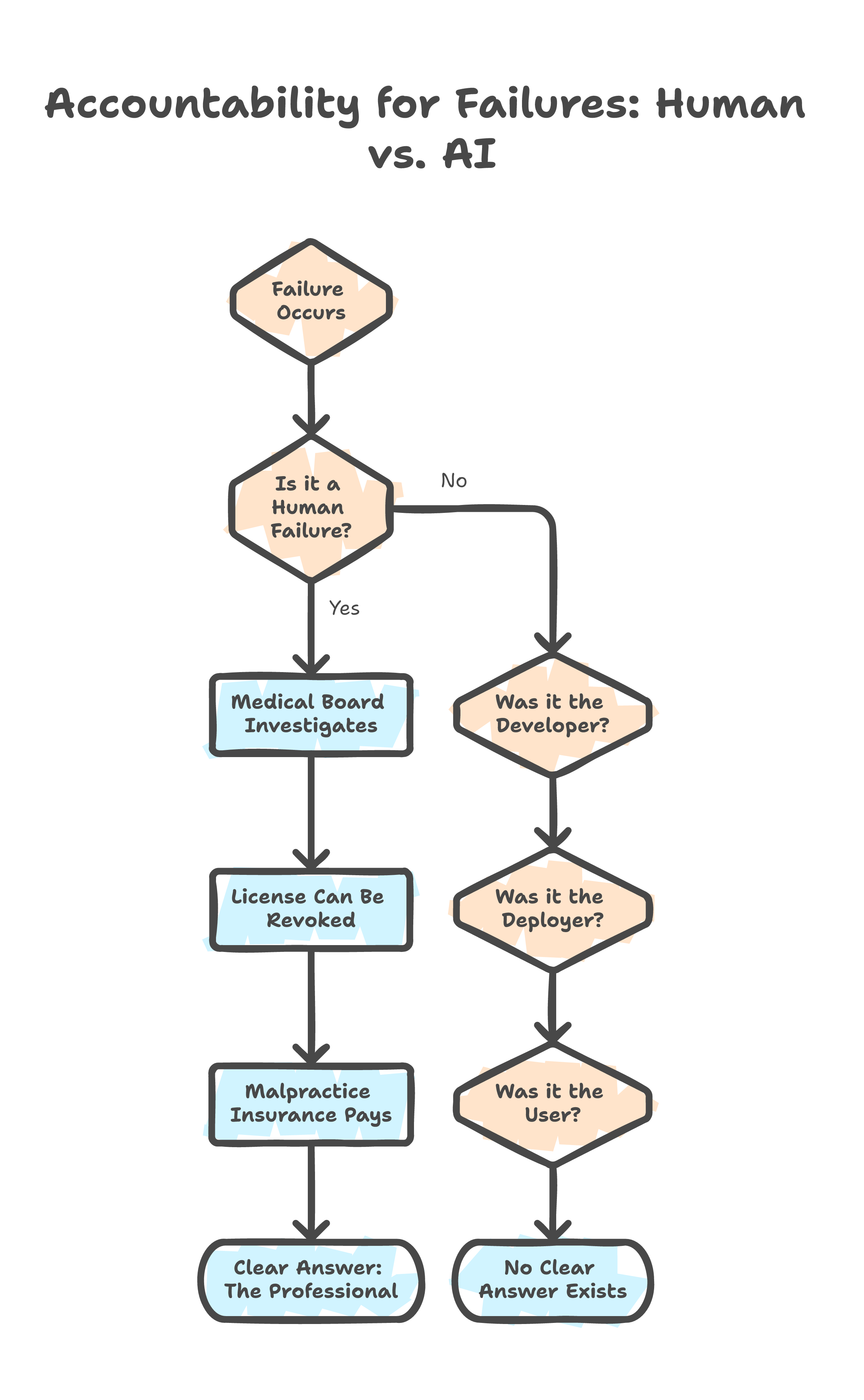
When a doctor makes an error, there is a medical board. When an engineer signs off on a flawed design, there is professional liability. When a financial advisor gives bad advice, there is a regulatory body and malpractice insurance. The systems are imperfect, but they are legible. You know who to call. You know who pays.
When AI fails, who do you call? The developer who trained the model? The company that deployed it? The user who trusted the output?
The question of accountability is genuinely unsolved. The EU AI Act tries to answer it. McKinsey's trust guidelines try. Internal governance policies try. None of them have a clean answer yet. I do not either.
The fear is not that AI makes mistakes. The fear is that nobody owns the mistake when it does.
The absence of an accountability framework does not mean the technology is less capable. It means we are behind on governance. Those are different problems. We did not stop using cars because liability law took decades to mature. We built the frameworks while we drove.
Meanwhile
This is a different domain. But the timing is hard to ignore.
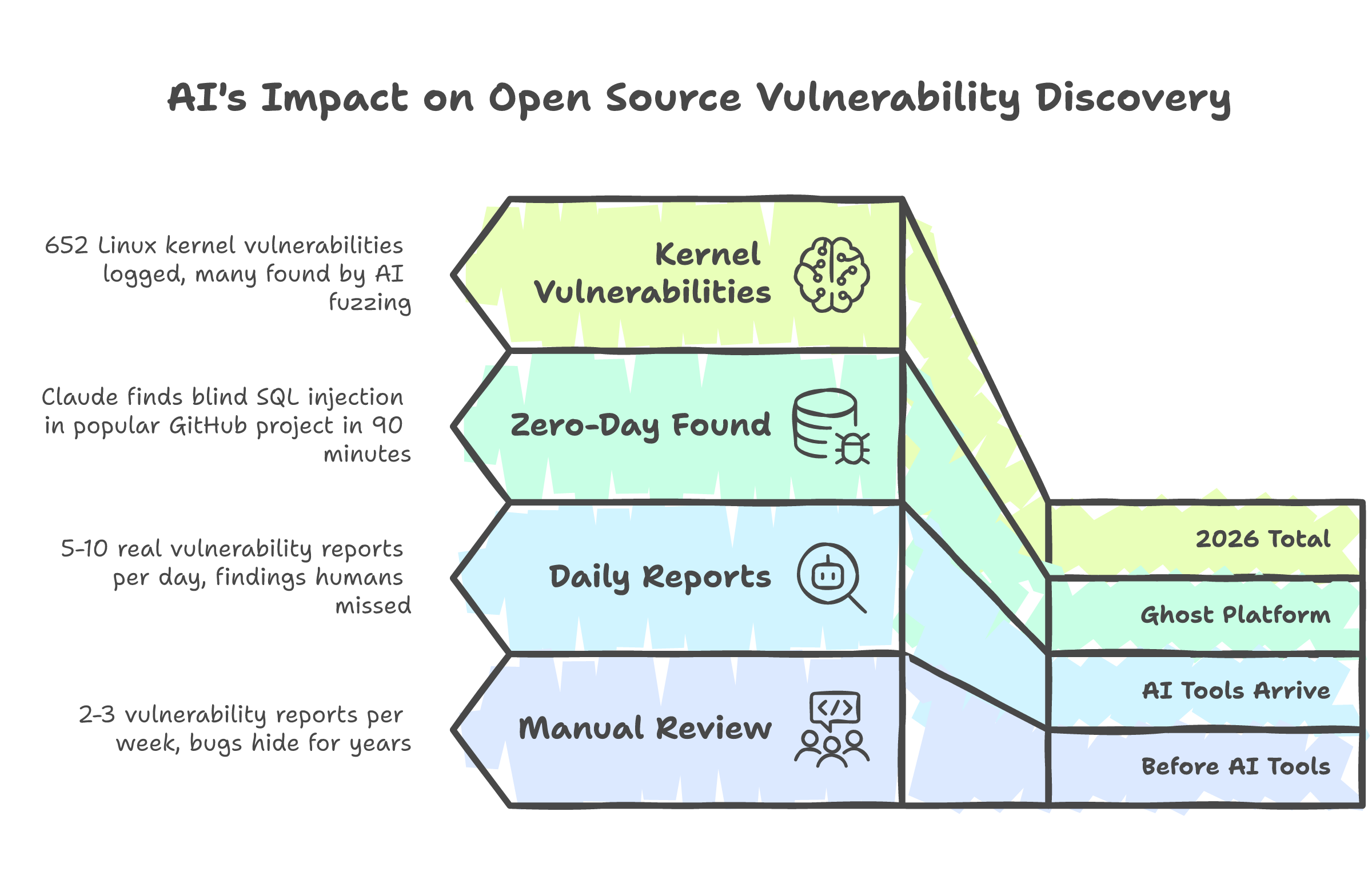
The Linux kernel security team reported that AI-generated vulnerability submissions had surged from two or three per week to five to ten per day. Not spam. Real bugs. Findings that human reviewers missed for years. Greg Kroah-Hartman, a Linux Foundation fellow, confirmed it: "The tools are good enough at finding these bugs."
The Open Source Security Foundation described the pace: submissions arriving "in minutes or hours" where they used to take weeks. Not one team. Multiple independent researchers, using different AI tools, finding the same bugs simultaneously. The old model of quiet disclosure and embargoed patches is breaking down because the bugs are being found faster than the process can handle.
At a conference demo, Claude found a blind SQL injection in Ghost, a platform with 50,000 GitHub stars that had never had a critical vulnerability in its entire history. Found it in 90 minutes. 652 Linux kernel vulnerabilities have been logged in 2026 so far, many discovered by AI tools running patterns no human team had the bandwidth to execute.
This does not prove AI is trustworthy for everything. Writing articles and finding SQL injections are different tasks. But it does raise a question: if we are going to hold AI to a higher standard, should we not also update that standard as the evidence changes?
What calibrated trust actually looks like
I do not think the answer is "trust AI" or "do not trust AI." The answer is: trust it for what it is measurably good at, verify where it is measurably weak, and invest in the governance structures that let you tell the difference.
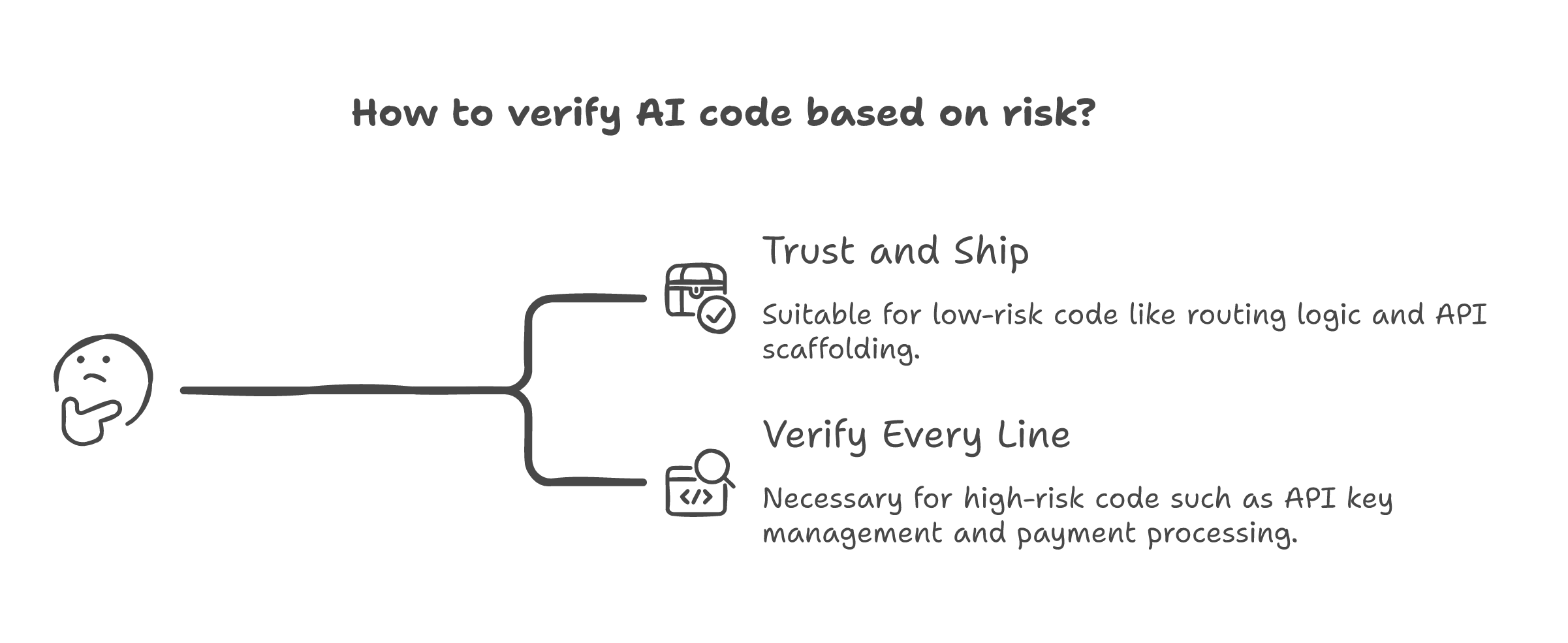
I build AI systems for a living. I let AI generate code all day. Routing logic, API scaffolding, data transformations, test boilerplate. It is fast and it is usually right. But when it comes to API key management or authentication modules, I review every line. Not because I think the model is bad at auth. Because the consequence of a subtle error in auth is different from the consequence of a subtle error in a data transform. One is a bug. The other is a breach.
That is calibrated trust. Not blanket acceptance. Not blanket rejection. Risk-proportional verification. The same approach we already use for human work. A junior developer can write a CRUD endpoint without oversight. That same developer gets a senior review before touching payment processing. We do not call that distrust. We call it engineering.
The problem is that most organizations do not apply this logic to AI. They either trust it completely (shadow AI, no review, no governance) or reject it completely ("it is not perfect"). Both responses are miscalibrated. Both cost more than the alternative.
What I actually think
I do not think we should trust AI blindly. Skepticism is fine. I would rather work with skeptics than with people who accept every output without reading it.
What I think is that we have a calibration problem. We assess AI risk based on how the technology makes us feel, not on what it actually gets wrong. A PMC study shows identical errors getting judged differently based on who made them. A 93-7 budget split shows organizations investing in the technology but not in helping people understand it. An accountability gap gets conflated with a capability gap.
With AI, the standard is still based on a guess. Fair. But the guess is narrowing. And the standard is not.
The double standard is not that we hold AI to higher expectations. It is that we forgot humans never met those expectations either.