Three months into building AiMod, our multi-agent DataOps platform, we had a demo that looked incredible. The agents routed tasks, generated SQL, orchestrated pipelines, and even explained their reasoning in clean markdown. Our stakeholders were impressed. Then we connected it to real data, and everything fell apart.
The SQL agent hallucinated column names that did not exist. The routing agent sent data quality tasks to the visualization agent. Two agents got stuck in an infinite retry loop that burned through our token budget in forty minutes. It was the kind of failure that makes you question whether this whole "agentic AI" thing is just a very expensive way to generate bugs.
The Demo Is Never the Product
That experience taught me something that I now consider the cardinal rule of production AI systems: the demo is never the product. What follows is the story of how we rebuilt, rearchitected, and eventually shipped 15 LangGraph agents that handle real workloads for Malaysia's first agentic AI DataOps/MLOps platform.
Why Most AI Agent Systems Fail in Production
Before I get into what we built, let me be honest about why the first version failed. And it was not because the models were bad.
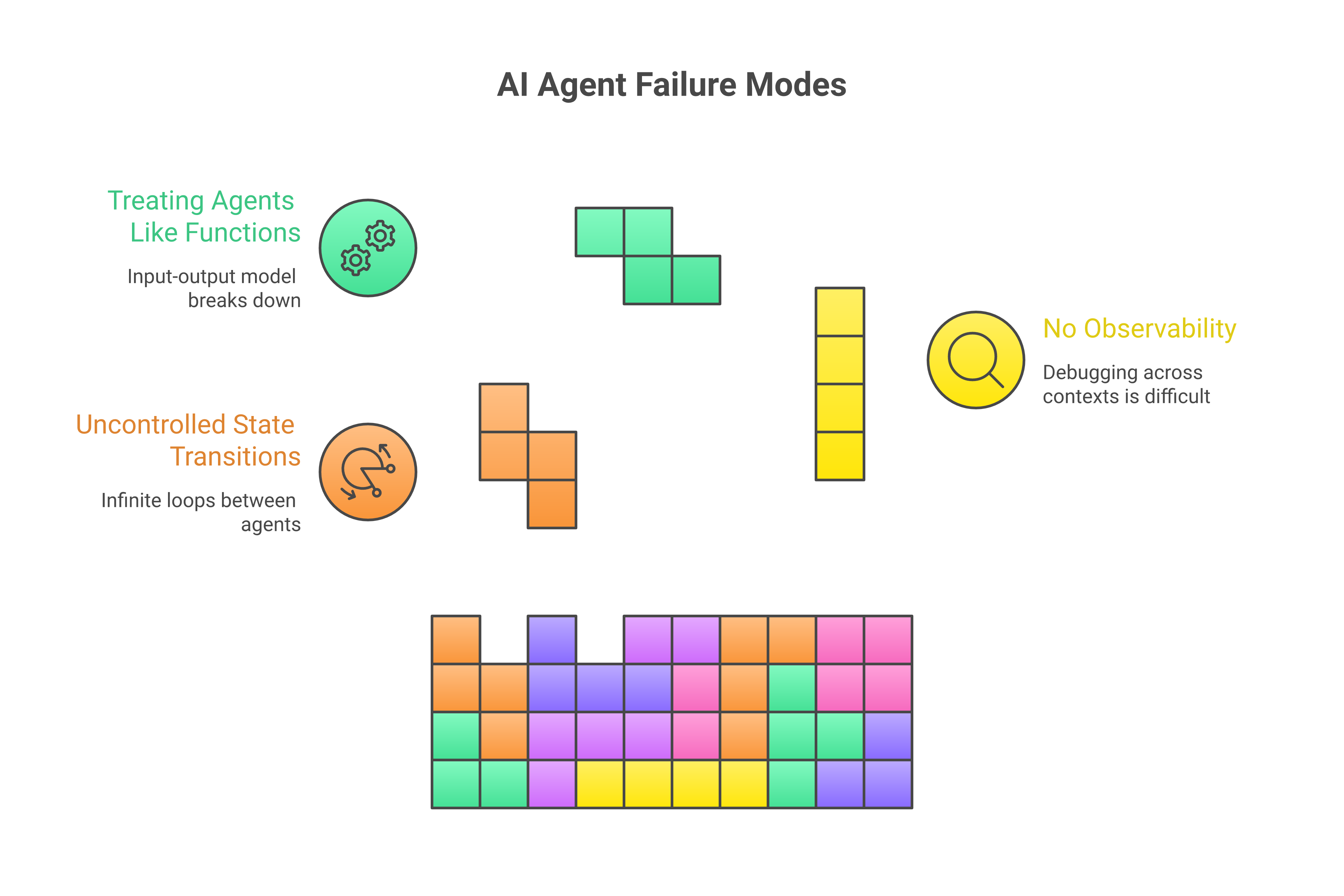
Most AI agent failures come down to three categories:
-
Uncontrolled state transitions. Without explicit guardrails on when and how agents hand off work, you get cascading failures. Agent A calls Agent B, which calls Agent C, which calls Agent A again. Congratulations, you have built a very sophisticated infinite loop.
-
No observability. When a single LLM call takes 2-8 seconds and you have five agents in a chain, debugging "why did the output look wrong" becomes archaeological work. You are sifting through logs trying to reconstruct a conversation that happened across multiple contexts.
-
Treating agents like functions. The mental model of "input goes in, output comes out" breaks down when your agent needs to handle ambiguous instructions, partial failures, and context that evolves mid-execution.
The Architecture That Actually Works
After the first failure, we stepped back and designed around three principles: explicit routing, bounded autonomy, and human-in-the-loop by default.
Decision Routing with LangGraph
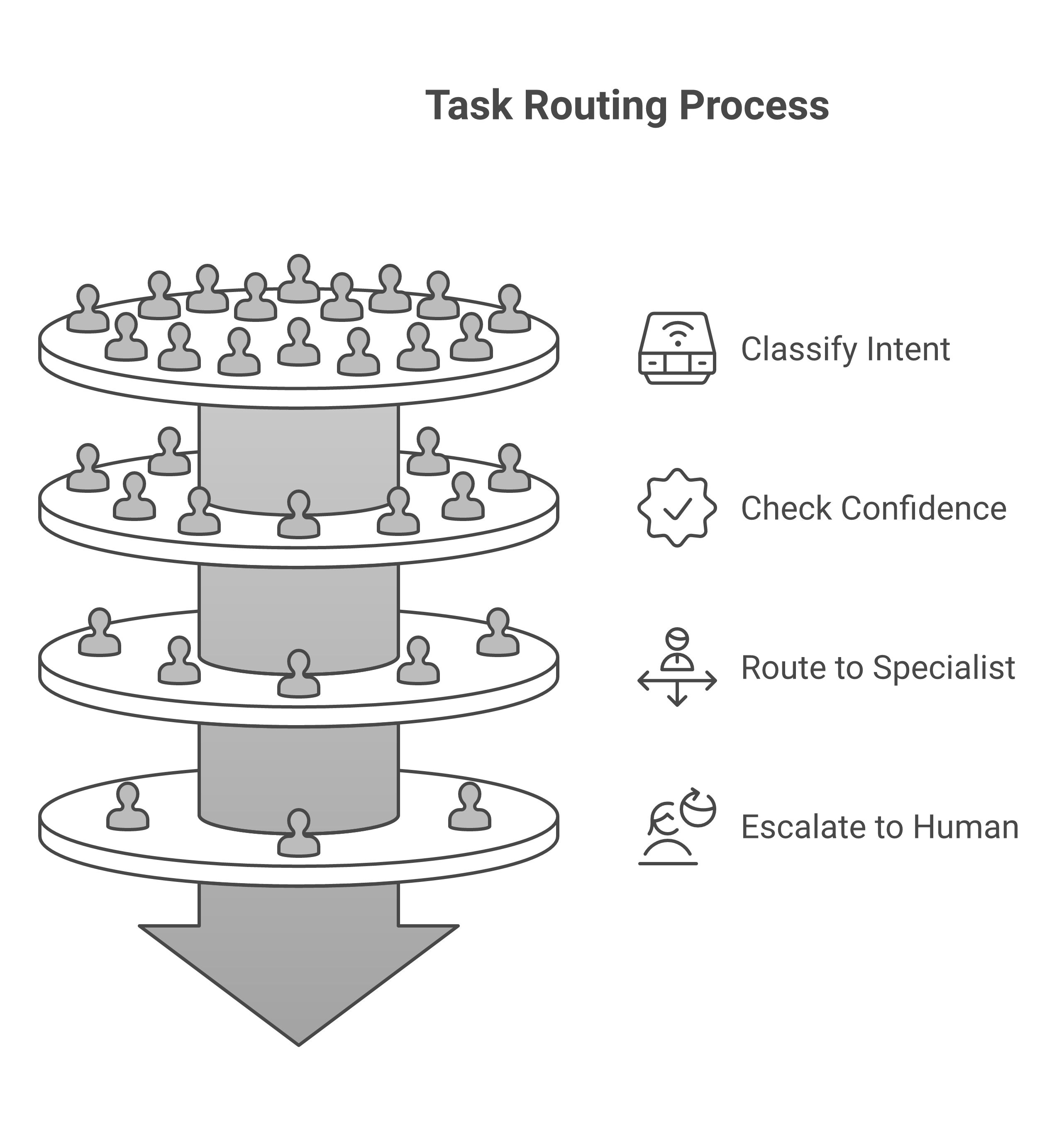
We use LangGraph's StateGraph as the backbone. Every agent interaction flows through a central routing layer that examines the task, classifies intent, and dispatches to the appropriate specialist agent.
class TaskRouter:
def route(self, state: AgentState) -> str:
task_type = state["task_classification"]
confidence = state["routing_confidence"]
if confidence < ROUTING_CONFIDENCE_THRESHOLD:
return "human_review"
return TASK_AGENT_MAP.get(task_type, "fallback_agent")
The 85% Confidence Threshold
The key insight here is the confidence threshold. If the router is not at least 85% confident about where to send a task, it escalates to a human. This single pattern eliminated roughly 60% of our misrouting errors overnight.
The Agent Taxonomy
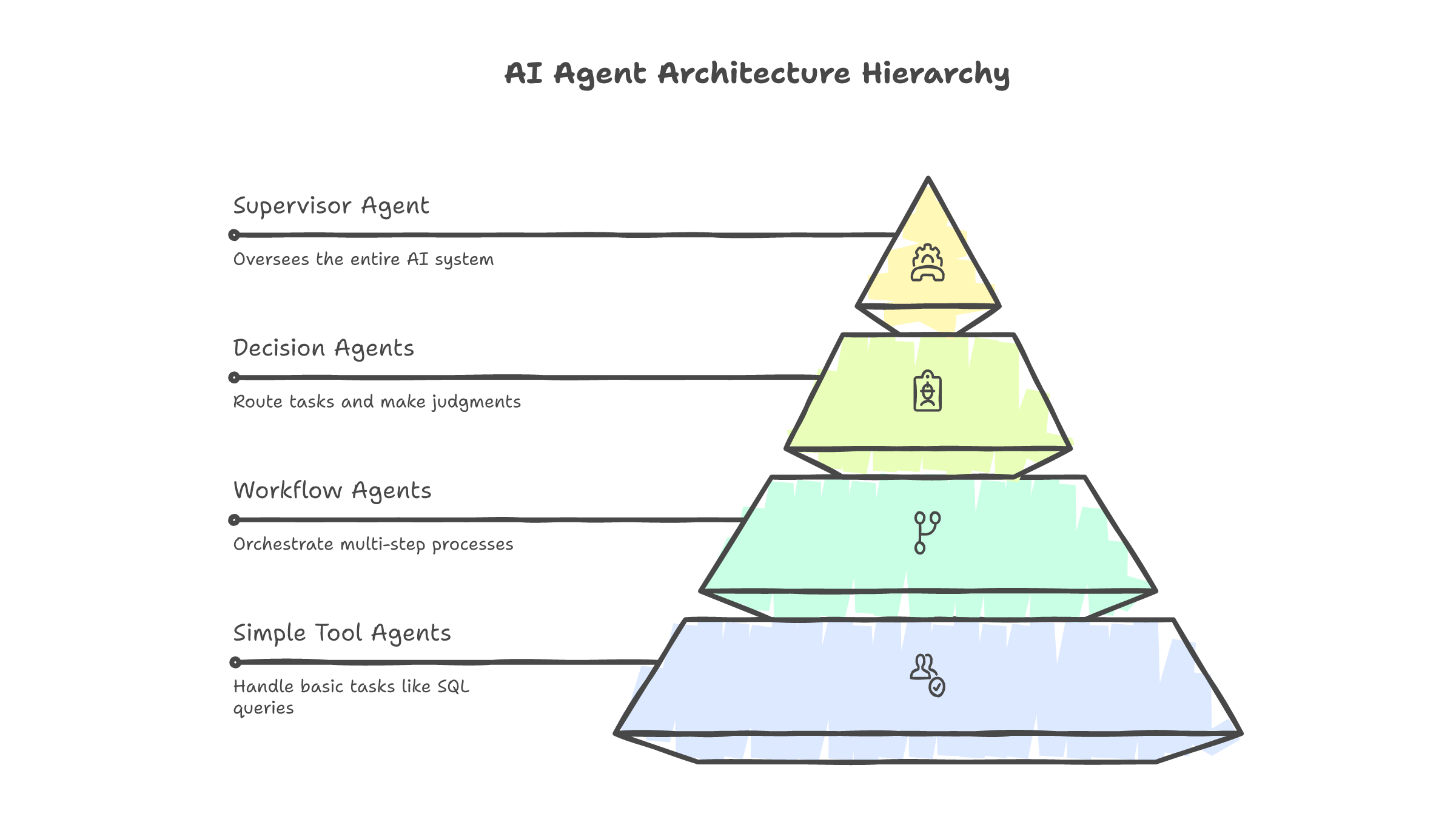
Our 15 agents fall into four tiers:
- Tier 1 -- Orchestration (2 agents): Task routing and workflow coordination. These agents never touch data directly. They are traffic controllers.
- Tier 2 -- Data Operations (5 agents): SQL generation, data profiling, schema validation, ETL monitoring, and anomaly detection. These are the workhorses.
- Tier 3 -- Intelligence (5 agents): ML model training orchestration, feature engineering suggestions, experiment tracking, model evaluation, and drift detection.
- Tier 4 -- Communication (3 agents): Report generation, natural language summarization, and alert management.
Each tier has its own error handling strategy and timeout configuration. Tier 2 agents, for instance, have strict 30-second timeouts because they interact with databases. Tier 3 agents get longer leashes because model training operations are inherently slower.
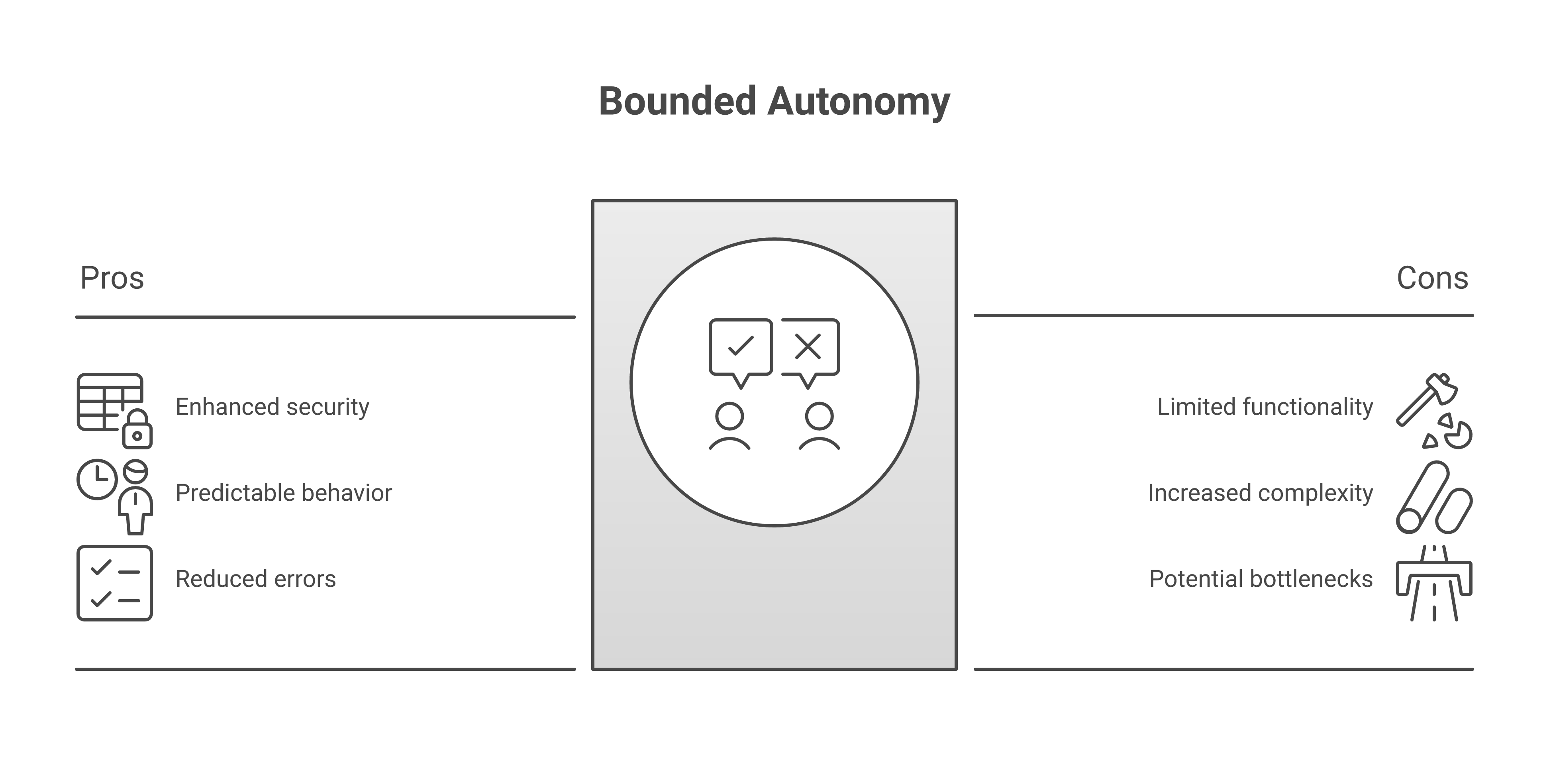
Bounded Autonomy: The Permission System
Every agent operates within a declared capability envelope. Here is a simplified version of what that looks like:
AGENT_PERMISSIONS = {
"sql_agent": {
"allowed_operations": ["SELECT", "WITH"],
"denied_operations": ["DROP", "DELETE", "UPDATE", "INSERT"],
"max_tables_per_query": 5,
"requires_approval": ["queries_touching_pii_tables"],
},
"etl_monitor_agent": {
"can_restart_failed_jobs": True,
"can_modify_schedules": False,
"max_auto_retries": 3,
},
}
Bounded Autonomy Over Full Autonomy
This is not just configuration -- it is a contract. Before any agent executes an action, a lightweight validation layer checks the action against the agent's declared permissions. If the SQL agent tries to generate a DELETE statement, it gets blocked before the query ever reaches the database.
Human-in-the-Loop: Not Optional, Not an Afterthought
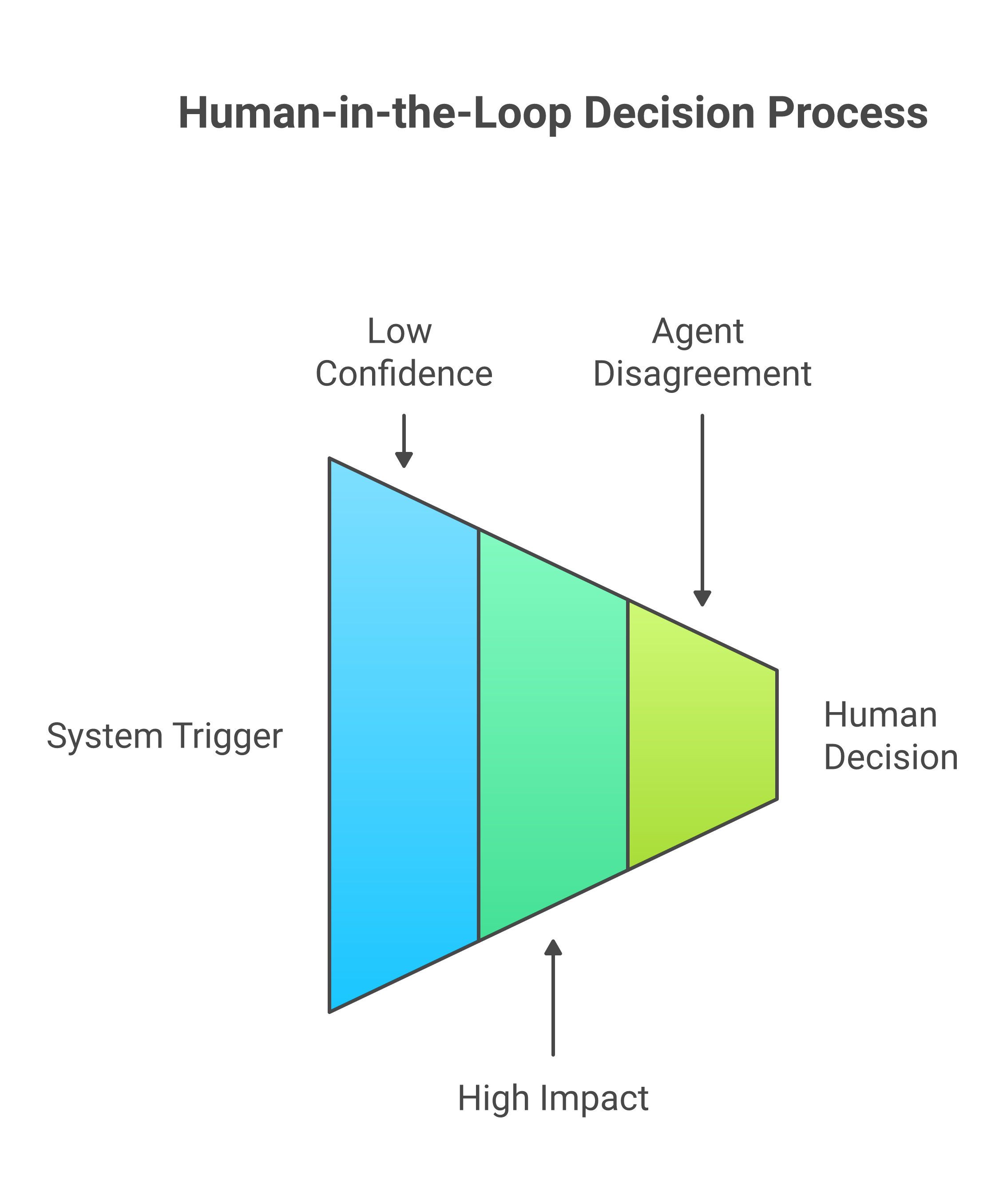
We designed human intervention as a first-class concept, not a fallback. There are three trigger points:
- Low routing confidence (< 85%): The system asks a human to confirm or redirect the task.
- High-impact actions: Anything that modifies data, triggers a pipeline, or affects production models requires explicit approval.
- Agent disagreement: When two agents produce conflicting assessments (e.g., the anomaly detector flags something the data profiler considers normal), a human arbitrates.
The approval workflow is async. We push pending approvals to a queue, notify the relevant team member, and the agent workflow pauses at a checkpoint until approval arrives. LangGraph's built-in persistence makes this surprisingly clean -- the agent state serializes to PostgreSQL, and we resume exactly where we left off.
Monitoring and Observability

You cannot run 15 agents in production without knowing what they are doing. We built a three-layer observability stack:
Layer 1 -- Trace-level logging. Every LLM call, tool invocation, and state transition is logged with a trace ID that correlates back to the original user request. We use structured JSON logs that feed into our monitoring dashboard.
Layer 2 -- Agent health metrics. Success rates, average latency, token consumption, and error rates per agent. When the SQL agent's success rate drops below 90%, we get an alert.
Layer 3 -- Business-level monitoring. How many tasks were completed successfully? How many required human intervention? What is the average time-to-resolution? These metrics matter more to stakeholders than p99 latencies.
@trace_agent_execution
async def execute_agent(agent_name: str, state: AgentState) -> AgentState:
start_time = time.monotonic()
try:
result = await agents[agent_name].ainvoke(state)
metrics.record_success(agent_name, time.monotonic() - start_time)
return result
except AgentTimeoutError:
metrics.record_timeout(agent_name)
return escalate_to_fallback(agent_name, state)
except Exception as e:
metrics.record_failure(agent_name, str(e))
return escalate_to_human(agent_name, state, error=e)
Lessons From the Trenches
After running this system in production across multiple enterprise clients, here is what I would tell someone starting out:
Start With Two Agents, Not Fifteen
Start with two agents, not fifteen. Get routing and one specialist agent working flawlessly before adding more. Every new agent multiplies the surface area for bugs.
Invest in your state schema early. The AgentState object is the most important data structure in your entire system. Get it wrong and you will be refactoring everything when you add your sixth agent.
Token budgets are production budgets. We track token consumption per agent per task type and set hard limits. An agent that burns 50K tokens on a simple data profiling task has a bug, full stop.
Test with adversarial inputs. We maintain a suite of ~200 adversarial test cases: ambiguous instructions, contradictory requirements, tasks that require capabilities the agents do not have. If your system cannot gracefully handle "I do not know how to do this," it is not production-ready.
What Comes Next
We are now working on agent-to-agent learning, where successful task completions from one agent inform the few-shot examples available to others. Early results are promising, but that is a story for another post.
Building AI agents that work at 3 AM when nobody is watching, on data they have never seen, for users who phrase requests in ways you never anticipated -- that is the actual engineering challenge.
The most important takeaway: building AI agents that demo well is easy. Building AI agents that work at 3 AM when nobody is watching, on data they have never seen, for users who phrase requests in ways you never anticipated -- that is the actual engineering challenge. And it is solvable, but only if you treat it as a systems problem, not a prompting problem.
If you are building multi-agent systems and want to compare notes, I am always up for a conversation. Reach out through my portfolio or connect with me on LinkedIn.