Yann LeCun and Fei-Fei Li agree the next era of AI is world models. They disagree on which part of reality matters most.
Two AI labs announced billion-dollar seed rounds within weeks of each other in 2026. Both claimed the same thing: large language models are not enough.
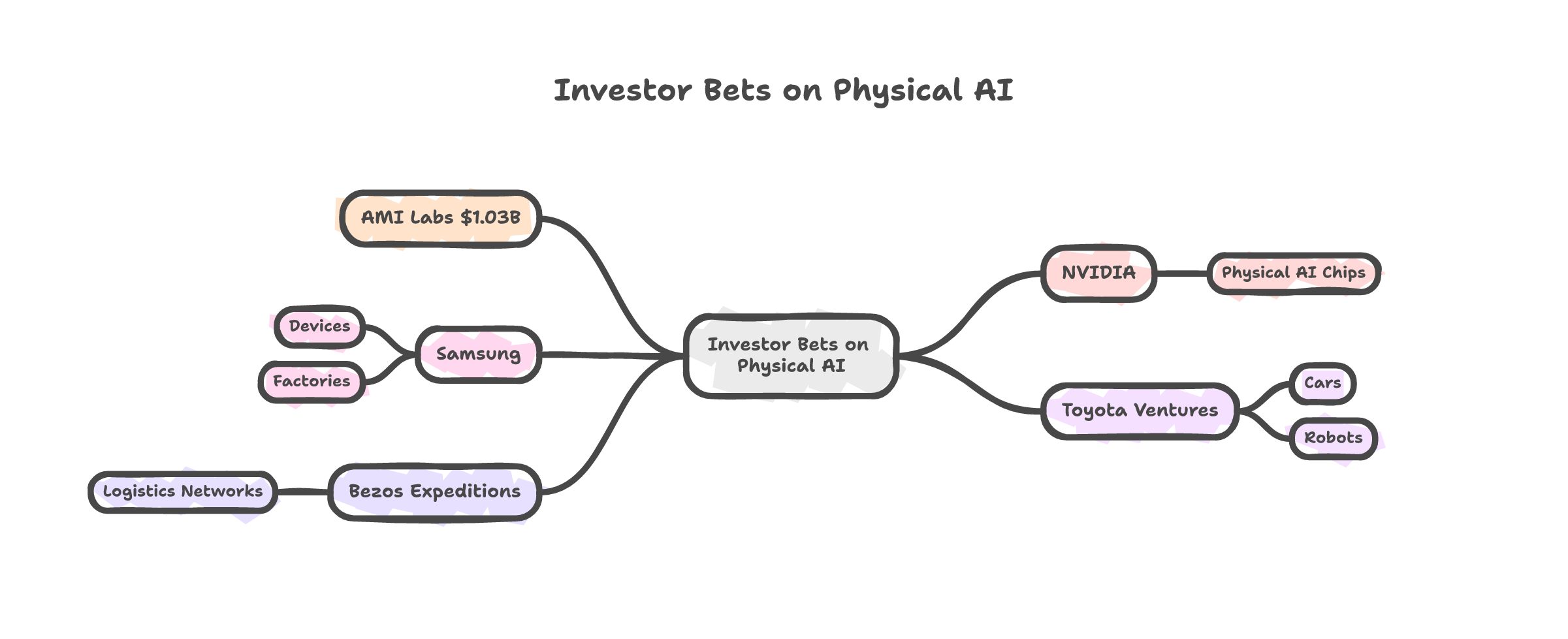
AMI Labs, founded by Turing Award winner Yann LeCun and former Nabla CEO Alex LeBrun, raised $1.03 billion. The largest seed round for a European company, possibly ever. Their thesis: AI needs to understand physics. How objects move, what happens when you drop something, why a bridge holds weight. The kind of knowledge a two-year-old has and GPT-4 does not.
World Labs, founded by Stanford professor Fei-Fei Li, raised $1 billion. Their thesis: AI needs to understand space. How a room looks from another angle, how light falls on a surface, how objects relate to each other in three dimensions. They already have a product shipping -- Marble, a 3D design tool.
Same diagnosis. Same scale of capital. Radically different prescriptions.
This matters because the "what comes after LLMs" question is no longer theoretical. Two of the most credentialed scientists in the field just bet their reputations that the answer is world models -- AI systems that simulate reality instead of predicting the next token. But they disagree on which part of reality matters most.
One is building AI that understands how things look. The other is building AI that understands how things work. The difference sounds subtle. The market implications are not.
What a two-year-old knows that ChatGPT does not
Ask ChatGPT what happens when you tilt a full cup of coffee. It will give you a paragraph about gravity, fluid dynamics, and surface tension. Accurate. Articulate. Completely useless in the moment.
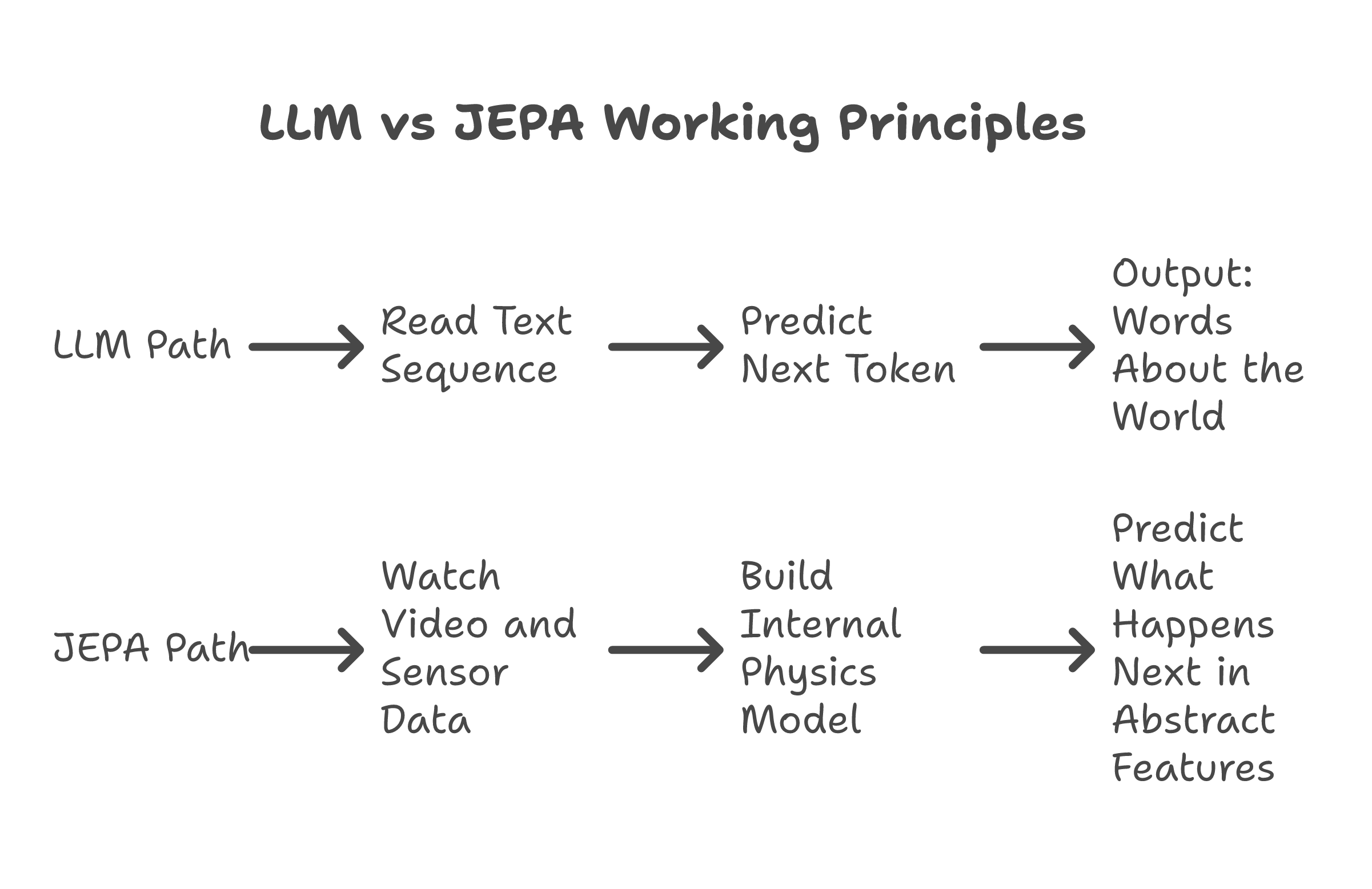
A two-year-old does not know the word "gravity." But she knows the coffee will spill. She knows it before it happens. She has a model of the world running in her head -- not a language model, a physics model. Objects fall. Liquids flow downhill. If you push something off a table, it does not hover.
This is the gap LeCun has been talking about for years. LLMs predict the next word. They do not predict the next event. They can describe what a ball does when you throw it. They cannot simulate the throw. The description and the simulation are different capabilities, and only one of them is useful for a robot trying to catch the ball.
A self-driving car approaches a construction zone. The camera sees orange cones. An LLM can label them. A world model simulates what happens if the car maintains speed versus braking versus changing lanes. The difference between labeling and simulating is the difference between seeing the cones and not hitting them.
A nurse watches a patient breathe. Nothing in the chart has changed. But the breathing pattern looks wrong. The nurse has a physical model of what "normal" looks like, built from thousands of hours of observation. Current AI reads the numbers on the monitor. It does not watch the patient breathe.
A factory robot picks up a glass bottle. It needs to know that glass is fragile before it squeezes, not after. That requires a model of materials, forces, and consequences.
The spatial intelligence bet
Fei-Fei Li is not wrong. She is solving a real problem.
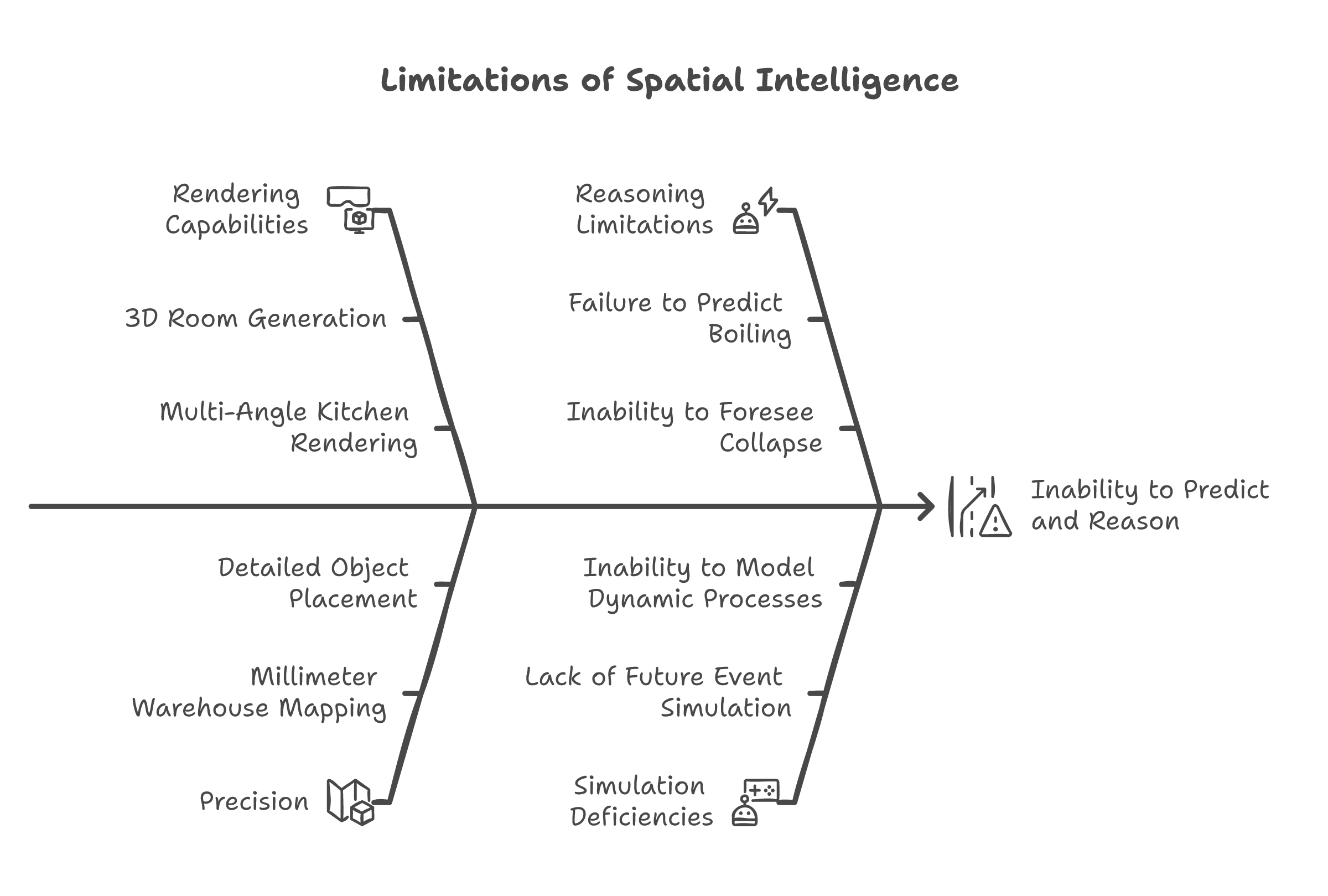
Her company, World Labs, builds what she calls "spatial intelligence" -- AI that understands three-dimensional space. Given a single photograph of a room, their system generates a full 3D model you can walk through. Change the lighting. Move the furniture. View it from any angle. Their product, Marble, already ships. Designers and architects use it.
Reconstructing 3D space from 2D images is a decades-old computer vision problem, and World Labs has pushed it further than most thought possible at consumer scale.
But notice what the system does and does not do. It answers: "What does this space look like from over there?" It does not answer: "What happens in this space if I do something?"
Marble can generate a photorealistic kitchen from every angle. It cannot tell you that the pot on the stove will boil over in three minutes. It can render a warehouse floor with millimeter precision. It cannot tell you that stacking those pallets that way will cause a collapse.
Spatial intelligence is a rendering problem. A valuable one. Gaming, architecture, and design need it. But the ceiling is visible. You are building better eyes for machines. Eyes that see from every angle, in perfect detail. The question is whether better eyes are enough, or whether machines also need intuition about what they are looking at.
Li raised a billion dollars to bet on eyes. LeCun raised a billion to bet on intuition.
The physics bet
LeCun's approach has a name -- JEPA, Joint Embedding Predictive Architecture. The name does not matter. What matters is what it does differently.
An LLM works like autocomplete. Given a sequence of words, predict the next word. Given a sequence of tokens, predict the next token. Pattern matching on language. Powerful, but it is a text trick at bottom.
JEPA works like imagination. Given a video of a ball rolling toward a wall, the system does not describe what happens next in words. It builds an internal representation of the scene and predicts what the scene will look like after the collision. Not in pixels -- in abstract features. Speed, direction, material properties, energy transfer. The system develops intuition, not vocabulary.
Think of it this way. An LLM reads a cookbook and can tell you the recipe for bread. JEPA watches someone make bread and understands that dough rises because of heat and yeast, that kneading changes texture, that timing matters. One knows the words. The other knows the physics.
This is why LeCun left Meta after twelve years. He believed -- publicly, repeatedly, and at professional cost -- that scaling LLMs would never produce systems that understand the world. That predicting the next token is a different capability from predicting the next event. Meta disagreed. LeCun walked.
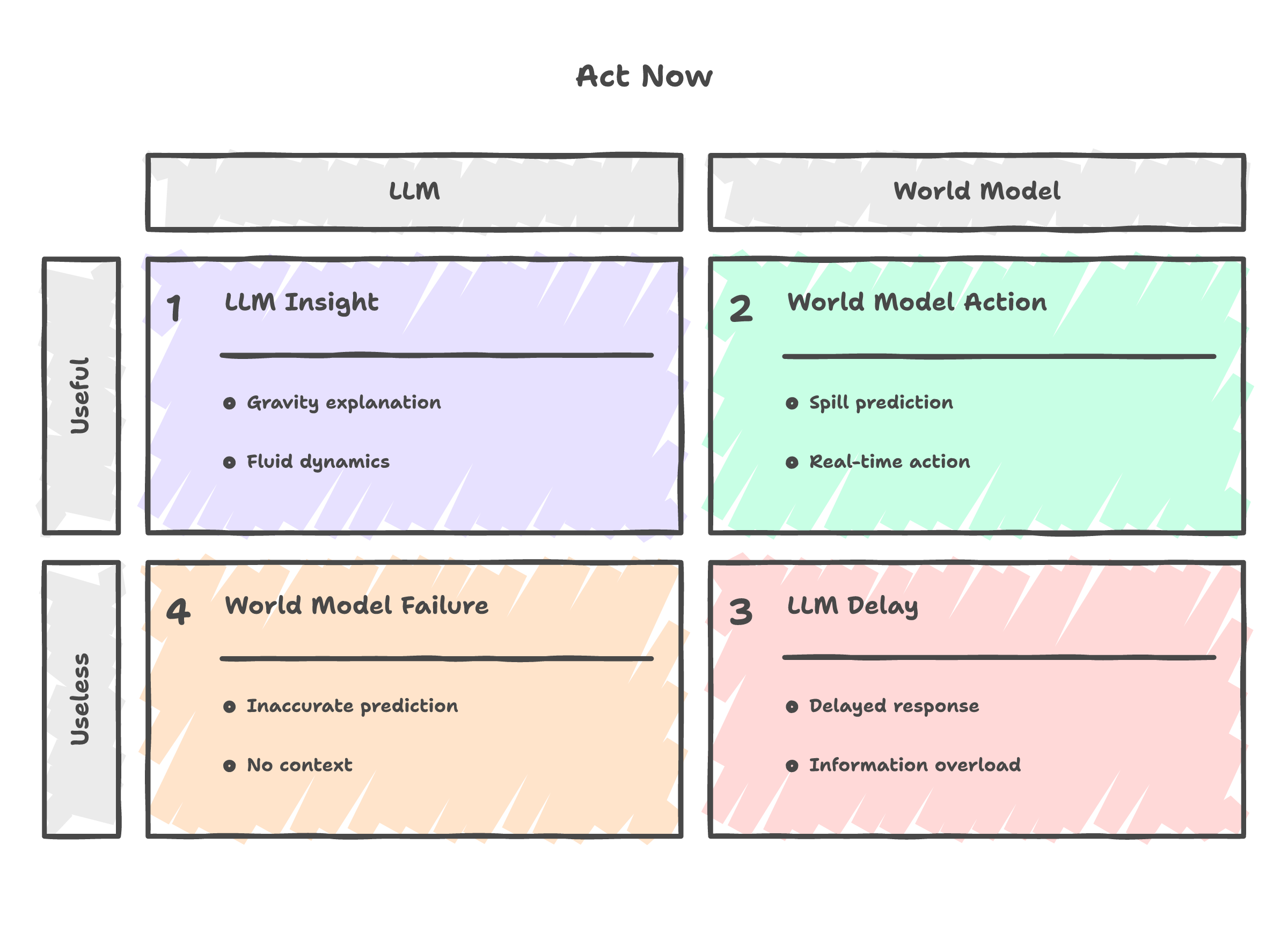
AMI's first target is healthcare. Not chatbots. Not image generation. Clinical decision support where the AI needs to simulate what happens to a patient if you choose treatment A versus treatment B. That requires causal reasoning. It requires a model of how bodies work, not a model of how medical textbooks read.
The distinction matters in practice. It is the difference between an AI that can quote the textbook and an AI that can think like the doctor.
Why one bet matters more than the other
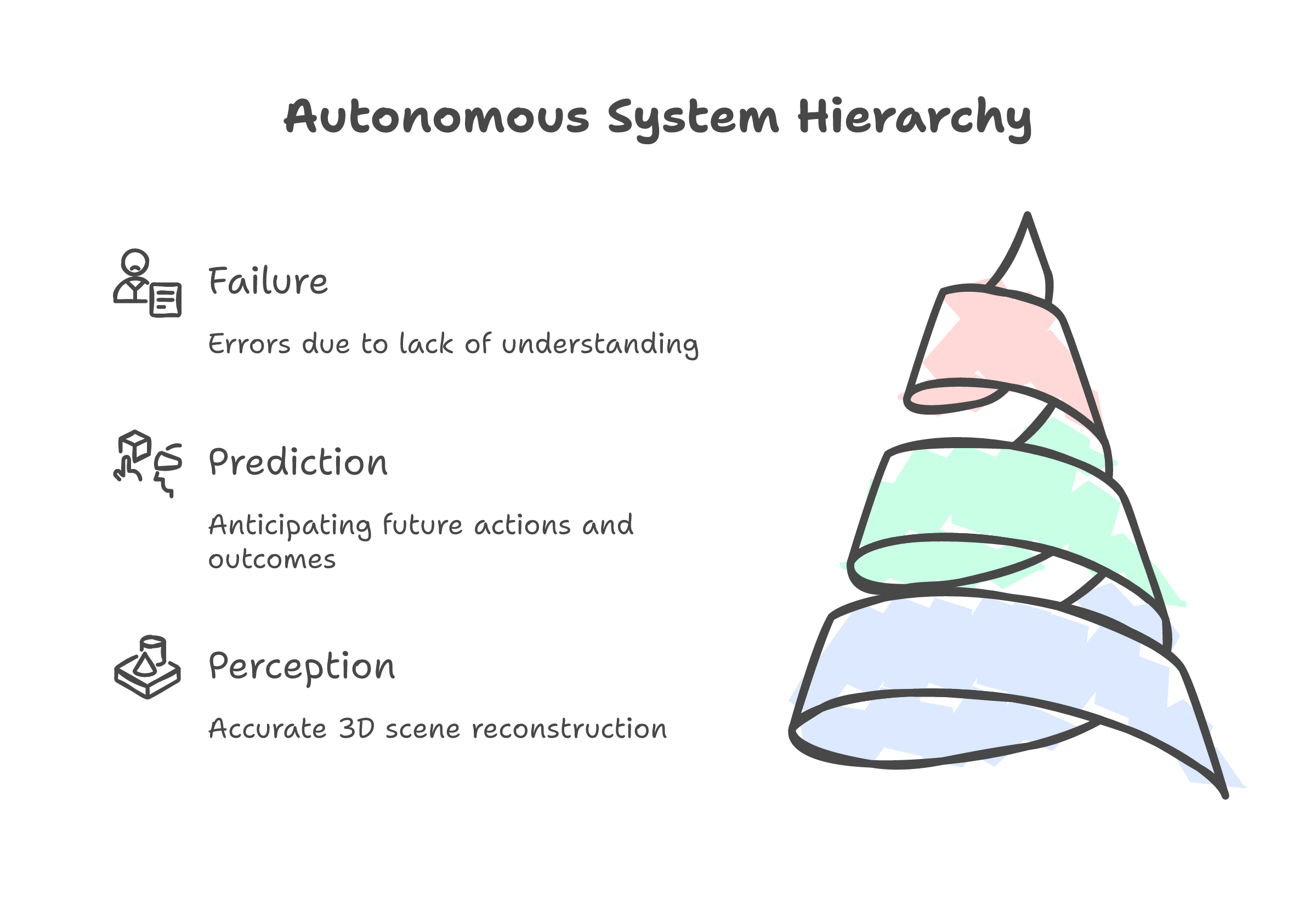
The hardest problems in production AI are never about what things look like. They are about what happens next.
Autonomous vehicles already have spatial intelligence. LiDAR gives you millimeter-accurate 3D. Tesla's vision system reconstructs the scene in real time. The cars still crash. Not because they cannot see the obstacle. Because they cannot predict what the pedestrian, the cyclist, the other driver will do in the next two seconds. Every fatal self-driving incident you have read about happened with full spatial awareness of the scene. The car saw everything. It understood nothing about what would happen next.
Surgical robots can map a patient's anatomy in 3D before the first incision. The hard part is not the map. It is knowing that this tissue will bleed differently from that tissue, that cutting here changes pressure there, that the plan needs to change mid-procedure because the body did something the textbook said it would not.
Same story in industrial automation. A robot arm that can see a conveyor belt in perfect 3D is commodity hardware. One that knows a warped part will jam the next machine downstream -- that is the version that runs a factory without a human watching.
Perception is largely solved. Prediction is not. And the market for predicting what happens next in the physical world is the physical world itself.
That is why LeCun's bet, if it works, reshapes more industries than Li's. The market for "what does this look like from another angle" fits inside the market for "what happens if I do this." One is contained by the other.
What happens if LeCun is right
If world models work -- if JEPA or something like it produces AI that genuinely understands physics -- LLMs become the dial-up era of AI. Useful, transformative for their time, and eventually a footnote. The same way dial-up proved the internet was valuable but nobody builds on it today. Token prediction got us this far. Physics simulation gets us the rest of the way.
The entire "scale the LLM" thesis -- the thesis that drove hundreds of billions in investment over the past four years -- would turn out to be a local maximum. Good enough to be convincing. Not good enough to be the answer.
The trillion-dollar question stops being "which company has the best LLM" and becomes "which company builds the first AI that understands cause and effect."
If LeCun is wrong, the story is simpler. He spent the largest European seed round in history on a theory he has championed for a decade, and the theory did not survive contact with engineering reality. World models join the list of beautiful ideas that worked on paper and broke at scale. It would not be the first time.
But here is what I keep coming back to. LeCun did not raise a billion dollars from his office. NVIDIA invested. Samsung invested. Toyota Ventures invested. Bezos invested. These are companies that build physical things -- chips, cars, factories, logistics networks. They are not betting on better chatbots. They are betting on AI that understands the world their products operate in.
That investor list is the tell.
Two scientists agree that LLMs are not enough. They disagree on what is. A billion dollars says one of them is right. The world models era just started, and it started with an argument.