Anthropic published a report on Monday accusing DeepSeek, Moonshot AI, and MiniMax of running coordinated campaigns to extract Claude's capabilities. 24,000 fake accounts. 16 million API exchanges. Proxy networks designed to evade detection. They called it "industrial-scale distillation."
The fraud part is clear. Fake accounts, proxy networks, circumventing regional access controls -- that is not a grey area. That is fraud. Prosecute it.
But the conversation did not stay there. Within hours, the framing shifted from "these companies committed fraud to access our API" to "distillation is theft." And that second framing is the one that should worry anyone who builds AI systems for a living.
Because if distillation is theft, I have some questions about my own work.
The framing problem
What I actually do for a living
I build multi-agent AI systems for enterprise clients in Malaysia. Financial institutions. Government-linked companies. Consulting firms. The systems run on local open-weight models -- Qwen, DeepSeek, GLM. Not cloud APIs. Everything runs on infrastructure we control.
A note on DeepSeek specifically: I use their open-weight models, which are freely licensed and run locally on our hardware. That is a different thing from what Anthropic is accusing DeepSeek-the-company of doing through fraudulent API access. I want to be clear about that distinction upfront.
The work ranges from document extraction pipelines to multi-agent DataOps platforms to RAG systems for regulated industries. Different clients, different problems, same pattern: LangGraph agents running on local open-weight models, coordinated through deterministic orchestration.
Over the course of building these systems, I learn things. Which prompt structures produce consistent output and which drift. How to route tasks between agents without them contradicting each other. Where a vision model is worth the cost and where text extraction is enough. What confidence thresholds actually mean in production versus what they mean on a benchmark.
That knowledge gets encoded into the system. Not into model weights. Into architecture. Into prompt templates. Into routing logic and validation rules and retry strategies. The system gets better over time because I learned from building it.
Is that distillation?
Where the knowledge lives
The line everyone is arguing about
Distillation, in the technical sense, means using a larger model's outputs to train a smaller model. You run prompts through GPT-5, collect the responses, and fine-tune a smaller model on those responses. The smaller model learns to mimic the larger one. That is distillation. It is a standard, well-documented ML technique. Anthropic uses it themselves to create lighter versions of Claude.
What I do is not that. I do not fine-tune models. I do not train on outputs. I build systems that use models as components.
But the knowledge transfer still happens. When I build a multi-agent pipeline and discover that chunking documents into 500-token segments with section headers produces better extraction than 1000-token segments without headers -- where did that knowledge come from? It came from running experiments against a model and observing what works. The model shaped the architecture. The architecture encodes what the model taught me.
If someone wants to call that distillation, they are going to have to call every software integration in history distillation. Every developer who ever read API documentation, experimented with different parameter settings, and built a system that works well with a particular service has "distilled" that service's capabilities into their architecture. Since when is that controversial?
Meanwhile, Hugging Face built a tool for it
While the discourse was busy arguing about whether distillation is theft, Hugging Face -- the largest open-source AI platform on the planet -- published a tool called upskill that does something very close to what Anthropic is complaining about.
The workflow is straightforward. You take a capable model (they call it the "teacher"), have it solve a hard problem, convert the solution into a reusable skill file, and transfer that skill to a cheaper or local model (the "student"). They tested it on writing CUDA kernels. Some open models saw 40% accuracy improvements with the right skill applied.
Teacher models. Student models. That is the vocabulary of distillation. Hugging Face is not hiding it behind proxy networks. They published it on GitHub with a README and a pip install command.
Nobody is calling Hugging Face criminals. Nobody is filing reports. The difference is that Hugging Face did not create 24,000 fake accounts to do it. They built a tool, published it openly, and let people use it. The method matters. The knowledge transfer itself is just engineering.
The quiet part out loud
The part that actually bothers me
There is another source of knowledge in every system I build, and nobody in this discourse is talking about it.
The client's domain expertise.
When I build a document extraction system for a financial institution, the extraction schema comes from the client. The validation rules come from the client. The definition of "correct" comes from the client's compliance team. The edge cases come from the client's ten years of processing these documents by hand.
I take that domain knowledge and encode it into the system. Into the prompt templates, the routing logic, the validation layer. Am I distilling the client? Am I stealing their institutional knowledge by building it into software?
Obviously not. That is what they are paying me to do. They are paying me to take their knowledge and make it operational. The model is just the execution engine.
The real source of value
But if we accept Anthropic's broadest framing -- that encoding knowledge from one source into another system is distillation, and distillation is theft -- then every consulting engagement I have ever done is theft. Every system integrator in the world is stealing from their clients. Every SaaS company that improves their product based on how customers use it is distilling their users.
That is absurd. But that is where the logic leads if you do not draw the line carefully.
Where the line actually is
Let me try to draw it, because the discourse is not doing a great job of this.
Clearly wrong: Creating 24,000 fake accounts, using proxy networks to evade access controls, systematically extracting capabilities through coordinated campaigns that violate terms of service. This is fraud. The access was unauthorized. The scale was designed to extract as much as possible while hiding the intent. Prosecute it.
Clearly fine: Paying for an API, using the outputs in your product, learning from the results to improve your system over time. This is what every API customer does. This is the entire business model of offering an API. If you sell access to a model and then complain when people learn from using it, you do not have a business model -- you have a contradiction.
The grey area: Using one model's outputs to directly train a competing model. This is technical distillation. It is not inherently illegal -- it depends on the terms of service, the license, and the jurisdiction. OpenAI's ToS prohibits it. Some open-weight model licenses allow it explicitly. The law has not caught up to the technology, and legal scholars are genuinely split on whether it constitutes IP infringement or fair use.
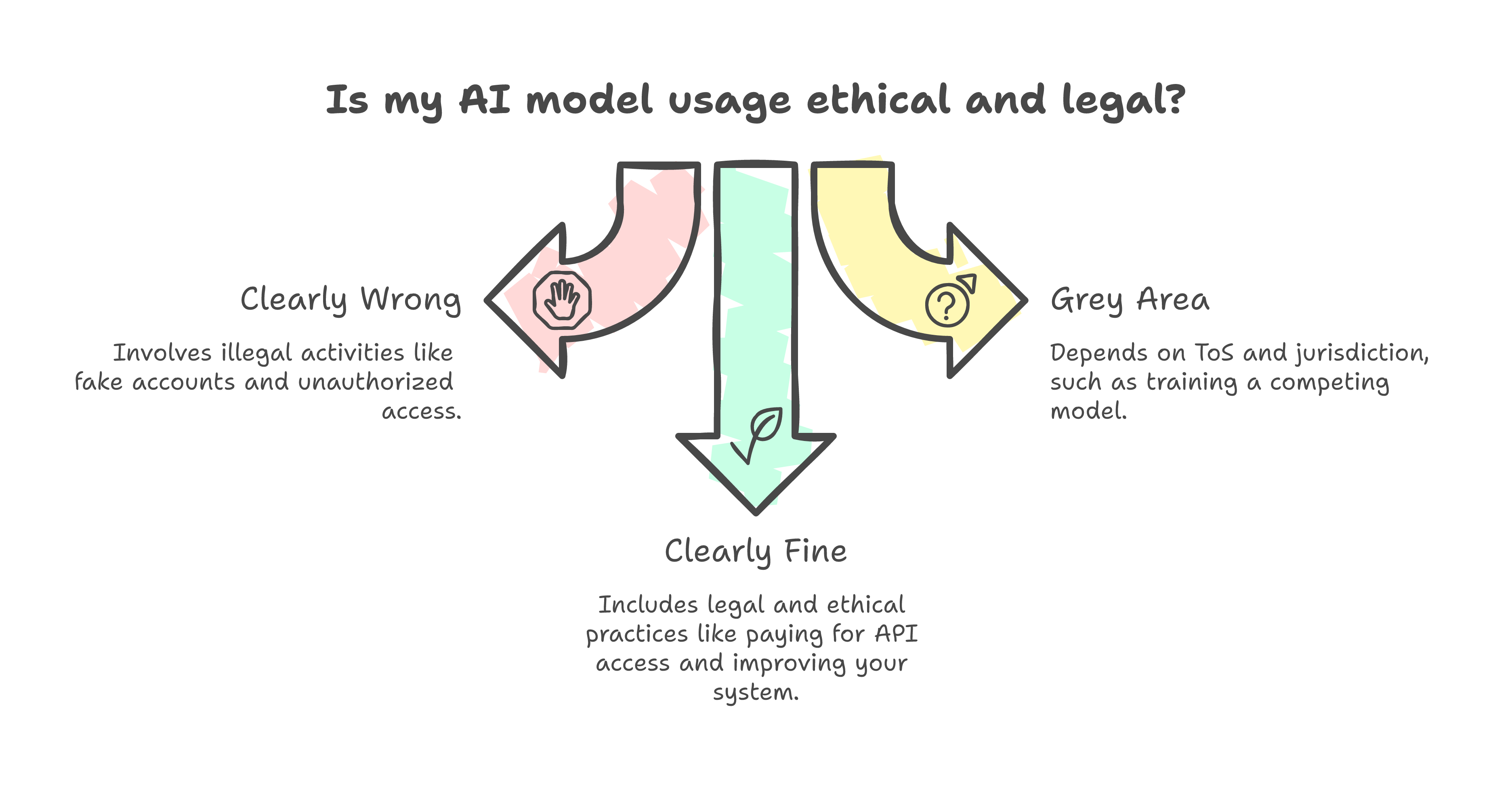
But here is the thing. The grey area is narrow. Most of what people actually do with AI models falls squarely in the "clearly fine" category. Building systems, learning from usage, improving architecture based on what works. That is software engineering. It has always been software engineering.
Drawing the line
The hypocrisy problem
This part is uncomfortable but I cannot write honestly about this topic without saying it.
Anthropic trained Claude on the open internet. Billions of web pages, scraped without asking, processed without permission. When challenged, they argue fair use. The same argument every foundation model company makes: the training data was publicly available, the transformation was sufficiently novel, the output does not reproduce the input.
Now someone uses Claude's outputs -- which Anthropic sold, through a commercial API, for money -- and Anthropic calls it theft.
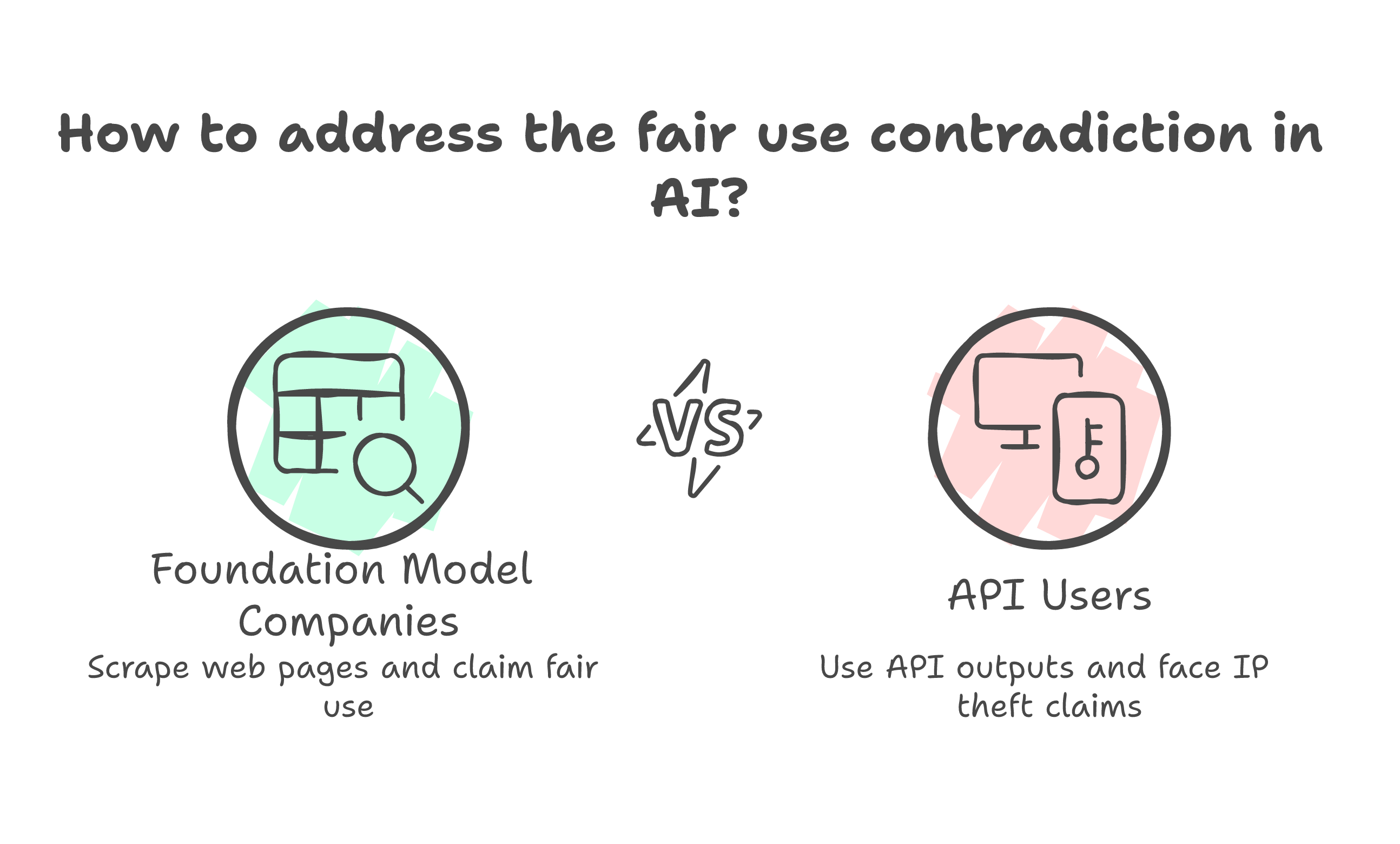
You cannot argue fair use when you are the one scraping and IP theft when you are the one being scraped. Not without looking like the rules only apply in the direction that benefits you.
I am not defending DeepSeek's methods. The fake accounts and proxy networks are indefensible. But if Anthropic's position is that distillation itself is the problem, not just the fraud, then they have a consistency issue that their legal team should think about carefully.
What I actually worry about
I do not worry about whether my work is distillation. It is not. I build systems, I do not train models.
What I worry about is the chilling effect. If the industry consensus moves toward "using model outputs to improve other systems is theft," that affects every AI solutions company on the planet. It affects every developer building on top of these APIs. It creates a world where you can buy a model's outputs but you are not allowed to learn from them.
That is a strange world. Imagine if Oracle argued that every developer who learned SQL by using their database was distilling Oracle's intellectual property. Imagine if AWS argued that every company that optimized their architecture based on experience with Lambda was stealing AWS's system design. The argument sounds absurd in those contexts. It should sound equally absurd in the AI context.
Models are tools. You use tools, you learn from them, you build better systems. The tool maker does not own the knowledge you gained from using their tool. They own the tool. They do not own your notes.
The chilling effect
I do not know where the legal lines will end up. The EU AI Act does not address distillation directly. US copyright law was not written with model outputs in mind. The courts will sort it out eventually, probably slowly, probably inconsistently across jurisdictions.
In the meantime, the distinction I keep coming back to is simple. Fraud is wrong. Learning is not. The method of access matters. The act of learning does not.
Since when is taking notes a crime?